What's new arround internet
| Src | Date (GMT) | Titre | Description | Tags | Stories | Notes |
| 2022-01-25 20:37:53 | An Exhaustively Analyzed IDB for ComLook (lien direct) | This blog entry announces the release of an exhaustive analysis of ComLook, a newly-discovered malware family about which little information has been published. It was recently discovered by ClearSky Cyber Security, and announced in a thread on Twitter. You can find the IDB for the main executable here, in which every function has been analyzed, and every data structure has been recovered.Like the previous two entries in this series on ComRAT v4 and FlawedGrace, I did this analysis as part of my preparation for an upcoming class on C++ reverse engineering. The analysis took about a one and a half days (done on Friday and Saturday). ComLook is an Outlook plugin that masquerades as Antispam Marisuite v1.7.4 for The Bat!. It is fairly standard as far as remote-access trojans go; it spawns a thread to retrieve messages from a C&C server over IMAP, and processes incoming messages in a loop. Its command vocabulary is limited; it can only read and write files to the victim server, run commands and retrieve the output, and update/retrieve the current configuration (which is saved persistently in the registry). See the IDB for complete details.(Note that if you are interested in the forthcoming C++ training class, it is nearing completion, and should be available in Q2 2022. More generally, remote public classes (where individual students can sign up) are temporarily suspended; remote private classes (multiple students on behalf of the same organization) are currently available. If you would like to be notified when public classes become available, or when the C++ course is ready, please sign up on our no-spam, very low-volume, course notification mailing list. (Click the button that says "Provide your email to be notified of public course availability".) )This analysis was performed with IDA Pro 7.7 and Hex-Rays 32-bit. All analysis has been done in Hex-Rays; go there for all the gory details, and don't expect much from the disassembly listing. All of the programmer-created data structures have been recovered and applied to the proper Hex-Rays variables. The functionality has been organized into folders, as in the following screenshot:
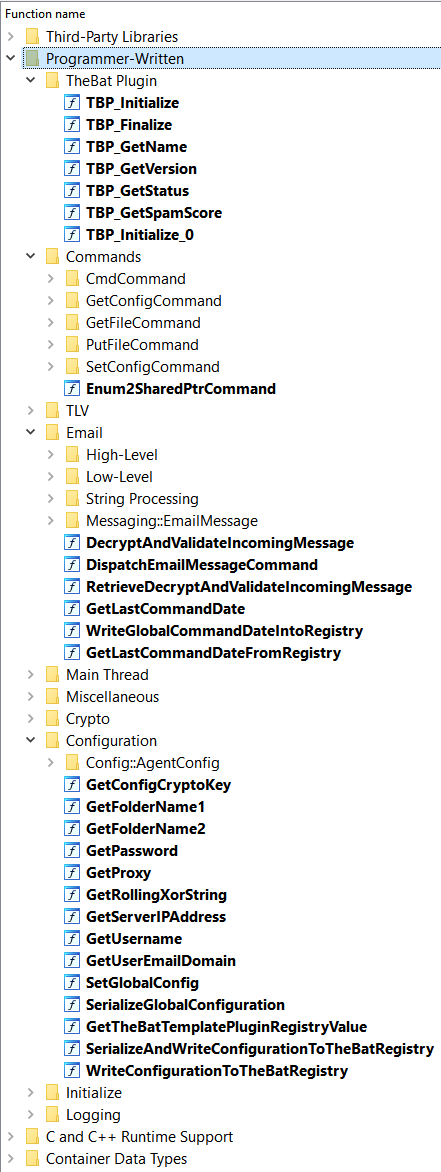 The binary was compiled with MSVC 10.0 with RTTI, and uses standard C++ template containers:string/wstringshared_ptrvectorlistmapThe primary difficulty in analyzing this sample was that it was compiled in debug mode. Although this does simplify some parts of the analysis (e.g., error message contain the raw STL typenames), it also slows the speed of comprehension due to a lack of inlining, and includes a huge amount of code to val
The binary was compiled with MSVC 10.0 with RTTI, and uses standard C++ template containers:string/wstringshared_ptrvectorlistmapThe primary difficulty in analyzing this sample was that it was compiled in debug mode. Although this does simplify some parts of the analysis (e.g., error message contain the raw STL typenames), it also slows the speed of comprehension due to a lack of inlining, and includes a huge amount of code to val |
Malware | |||
| 2021-09-21 19:57:00 | Automation in Reverse Engineering C++ STL/Template Code (lien direct) | There are three major elements to reverse engineering C++ code that uses STL container classes: Determining in the first place that an STL container is being used, and which category, i.e., std::list vs. std::vector vs. std::set Determining the element type, i.e., T in the categories above Creating data types in your reverse engineering tool of choice, and applying those types to the decompilation or disassembly listing. Though all of those elements are important, this entry focuses on the last one: creating instantiated STL data types, and more specifically, types that can be used in Hex-Rays. The main contribution of this entry is simply its underlying idea, as I have never seen it published anywhere else; the code itself is simple enough, and can be adapted to any reverse engineering framework with a type system that supports user-defined structures. I have spent the pandemic working on a new training class on C++ reverse engineering; the images and concepts in this blog entry are taken from the class material. The class goes into much more depth than this entry, such as by material on structure and type reconstruction, and having individual sections on each of the common STL containers. (If you are interested in the forthcoming C++ training class, it will be completed early next year, and available for in-person delivery when the world is more hospitable. If you would like to be notified when public in-person classes for the C++ course is ready, please sign up on our no-spam, very low-volume, course notification mailing list. (Click the button that says "Provide your email to be notified of public course availability".) ) Overview and MotivationAt a language level, C++ templates are one of the most complex features of any mainstream programming language. Their introduction in the first place -- as opposed to a restricted, less-powerful version -- was arguably a bad mistake. They are vastly overcomplicated, and in earlier revisions, advanced usage was relegated to true C++ experts. Over time, their complexity has infested other elements of the language, such as forming the basis for the C++11 auto keyword. However, the basic, original ideas behind C++ templates were inconspicuous enough, and are easy to explain to neophytes. Moreover, reverse engineers do not need to understand the full complexity of C++ templates for day-to-day work. Let's begin with a high-level overview of which problems in C software development that C++ templates endeavored to solve, and roughly how they solved them. Put simply, many features of C++ were designed to alleviate situations where common practice in C was to copy and paste existing code and tweak it slightly. In particular, templates alleviate issues with re-using code for different underlying data types. C does offer one alternative to copy-and-paste in this regard -- the macro preprocessor -- though it is a poor, cumbersome, and limited solution. Let's walk through a small real-world example. Suppose we had code to shuffle the contents of a char array, and we wanted to re-use it to shuffle int arrays. | Tool Guideline | |||
| 2021-06-02 00:10:45 | Hex-Rays, GetProcAddress, and Malware Analysis (lien direct) | This entry is about how to make the best use of IDA and Hex-Rays with regards to a common scenario in malware analysis, namely, dynamic lookup of APIs via GetProcAddress (and/or import resolution via hash). I have been tempted to write this blog entry several times; in fact, I uploaded the original code for this entry exactly one year ago today. The problem that the script solves is simple: given the name of an API function, retrieve the proper type signature from IDA's type libraries. This makes it easier for the analyst to apply the proper types to the decompilation, which massively aid in readability and presentability. No more manually looking up and copying/pasting API type definitions, or ignoring the problem due to its tedious solution; just get the information directly from the IDA SDK. Here is a link to the script.
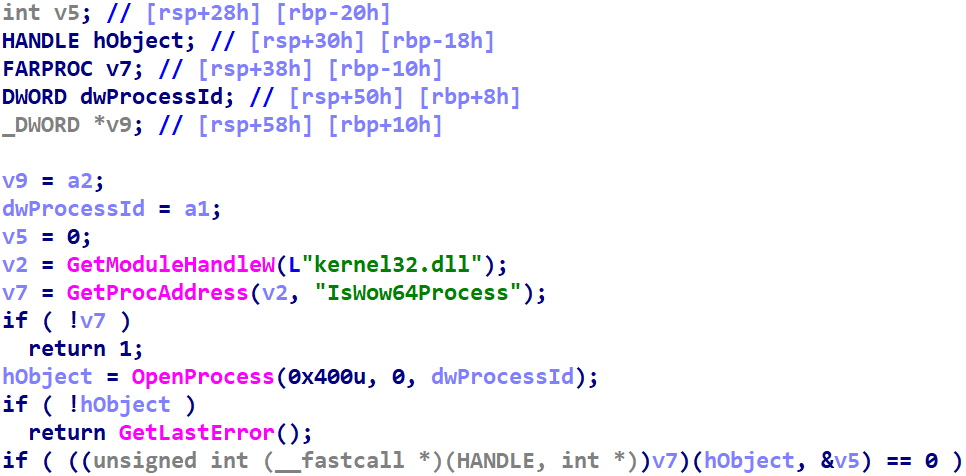
BackgroundHex-Rays v7.4 introduced special handling for GetProcAddress. We can see the difference -- several of them, actually -- in the following two screenshots. The first comes from Hex-Rays 7.1:
 The second comes from Hex-Rays 7.6:
The second comes from Hex-Rays 7.6:
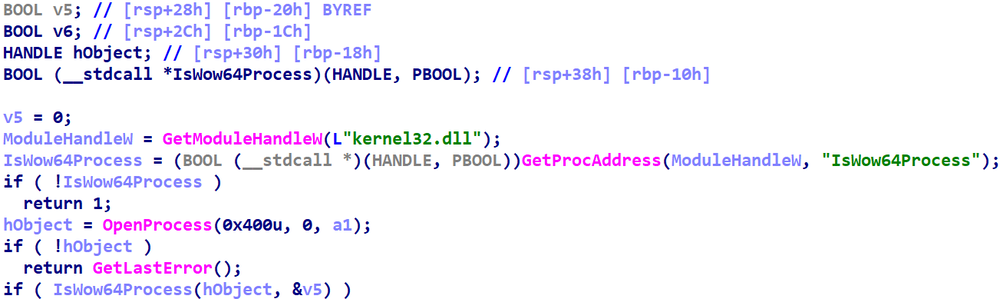 Several new features are evident in the screenshots -- more aggressive variable mapping eliminating the first two lines, and automatic variable renaming changing the names of variables -- but the one this entry focuses on has to do with the type assigned to the return value of GetProcAddress. Hex-Rays v7.4+ draw upon IDA's type libraries to automatically resolve the name of the procedure to its proper function pointer type signature, and set the return type of GetProcAddress to that type.
This change is evident in the screenshots above:
Several new features are evident in the screenshots -- more aggressive variable mapping eliminating the first two lines, and automatic variable renaming changing the names of variables -- but the one this entry focuses on has to do with the type assigned to the return value of GetProcAddress. Hex-Rays v7.4+ draw upon IDA's type libraries to automatically resolve the name of the procedure to its proper function pointer type signature, and set the return type of GetProcAddress to that type.
This change is evident in the screenshots above: |
Malware | |||
| 2021-03-03 23:59:27 | What is a while(2) loop in Hex-Rays? (lien direct) | Hex-Rays uses while(1) to represent infinite loops in the output. However, sometimes you might see while(2) loops in the output instead, as in the following:
 Logically, while(2) behaves the same as while(1) -- both loops are infinite -- but I wondered where they came from, what they meant, and why Hex-Rays produces them. Given that somebody asked me about it on Twitter, it's clear that I'm not the only one who's had this question. I recently learned the answer, so I decided to document it for posterity.
Answering this question requires some discussion of Hex-Rays internals. The decompiler operates in two major phases, known internally as "microcode" and "ctree". The microcode phase covers the core decompilation logic, such as: translating the assembly instructions into an intermediate representation; applying compiler-esque transformations such as data flow analysis, constant propagation, forward substitution, dead store elimination, and so on; analyzing function calls; and more. To learn more, I'd recommend reading Ilfak's blog entry and installing the Lucid microcode explorer.
The ctree analysis phases, on the other hand, are more focused on the listing that gets presented to the user. The ctree phase contains relatively little code that resembles standard compiler optimizations -- some pattern transformations are close -- whereas much of the code in the microcode phase resembles standard compiler analysis. The major differences between the two are that the microcode does not have high-level control flow structures such as loops (it uses goto statements and assembly-like conditional branches instead), and that type information plays a relatively minor role in the microcode phase, whereas it plays a major role in the ctree phase.
Between the microcode and ctree phases, there is a brief phase known internally as hxe_structural, which performs so-called "structural analysis". This phase operates on the final microcode, after all analysis and transformation, but before the ctree has been constructed. Its role is to determine which high-level control flow structures should be presented to the user in the ctree listing. I.e., the information generated by this phase is used during ctree generation to create if, if/else, while, do/while, switch, and goto statements.
After ctree generation is complete, Hex-Rays applies two sets of transformations (known internally as CMAT_TRANS1 and CMAT_TRANS2) to the decompilation listing, to clean up common patterns of suboptimal output. For example, given the following code:
if(cond) { result = 1;
Logically, while(2) behaves the same as while(1) -- both loops are infinite -- but I wondered where they came from, what they meant, and why Hex-Rays produces them. Given that somebody asked me about it on Twitter, it's clear that I'm not the only one who's had this question. I recently learned the answer, so I decided to document it for posterity.
Answering this question requires some discussion of Hex-Rays internals. The decompiler operates in two major phases, known internally as "microcode" and "ctree". The microcode phase covers the core decompilation logic, such as: translating the assembly instructions into an intermediate representation; applying compiler-esque transformations such as data flow analysis, constant propagation, forward substitution, dead store elimination, and so on; analyzing function calls; and more. To learn more, I'd recommend reading Ilfak's blog entry and installing the Lucid microcode explorer.
The ctree analysis phases, on the other hand, are more focused on the listing that gets presented to the user. The ctree phase contains relatively little code that resembles standard compiler optimizations -- some pattern transformations are close -- whereas much of the code in the microcode phase resembles standard compiler analysis. The major differences between the two are that the microcode does not have high-level control flow structures such as loops (it uses goto statements and assembly-like conditional branches instead), and that type information plays a relatively minor role in the microcode phase, whereas it plays a major role in the ctree phase.
Between the microcode and ctree phases, there is a brief phase known internally as hxe_structural, which performs so-called "structural analysis". This phase operates on the final microcode, after all analysis and transformation, but before the ctree has been constructed. Its role is to determine which high-level control flow structures should be presented to the user in the ctree listing. I.e., the information generated by this phase is used during ctree generation to create if, if/else, while, do/while, switch, and goto statements.
After ctree generation is complete, Hex-Rays applies two sets of transformations (known internally as CMAT_TRANS1 and CMAT_TRANS2) to the decompilation listing, to clean up common patterns of suboptimal output. For example, given the following code:
if(cond) { result = 1; |
||||
| 2021-03-02 19:47:11 | An Exhaustively-Analyzed IDB for FlawedGrace (lien direct) | This blog entry announces the release of an exhaustive analysis of FlawedGrace. You can find the IDB for the main executable, and for the 64-bit password stealer module, here. The sha1sum for the main executable is 9bb72ae1dc6c49806064992e0850dc8cb02571ed, and the md5sum is bc91e2c139369a1ae219a11cbd9a243b.Like the previous entry in this series on ComRAT v4, I did this analysis as part of my preparation for an upcoming class on C++ reverse engineering. The analysis took about a month, and made me enamored with FlawedGrace's architecture. I have personally never analyzed (nor read the source for) a program with such a sophisticated networking component. Were I ever to need a high-performance, robust, and flexible networking infrastructure, I'd probably find myself cribbing from FlawedGrace. This family is also notable for its custom, complex virtual filesystem used for configuration management and C2 communications. I would like to eventually write a treatise about all of the C++ malware family analyses that I performing during my research for the class, but that endeavor was distracting me from work on my course, and hence will have to wait.(Note that if you are interested in the forthcoming C++ training class, it probably will be available in Q3/Q4 2021. More generally, remote public classes (where individual students can sign up) are temporarily suspended; remote private classes (multiple students on behalf of the same organization) are currently available. If you would like to be notified when public classes become available, or when the C++ course is ready, please sign up on our no-spam, very low-volume, course notification mailing list. (Click the button that says "Provide your email to be notified of public course availability".) )(Note that I am looking for a fifth and final family (beyond ComRAT, FlawedGrace, XAgent, and Kelihos) to round out my analysis of C++ malware families. If you have suggestions -- and samples, or hashes I can download through Hybrid-Analysis -- please send me an email at rolf@ my domain.)About the IDBHere are some screenshots. First, a comparison of the unanalyzed executable versus the analyzed one:
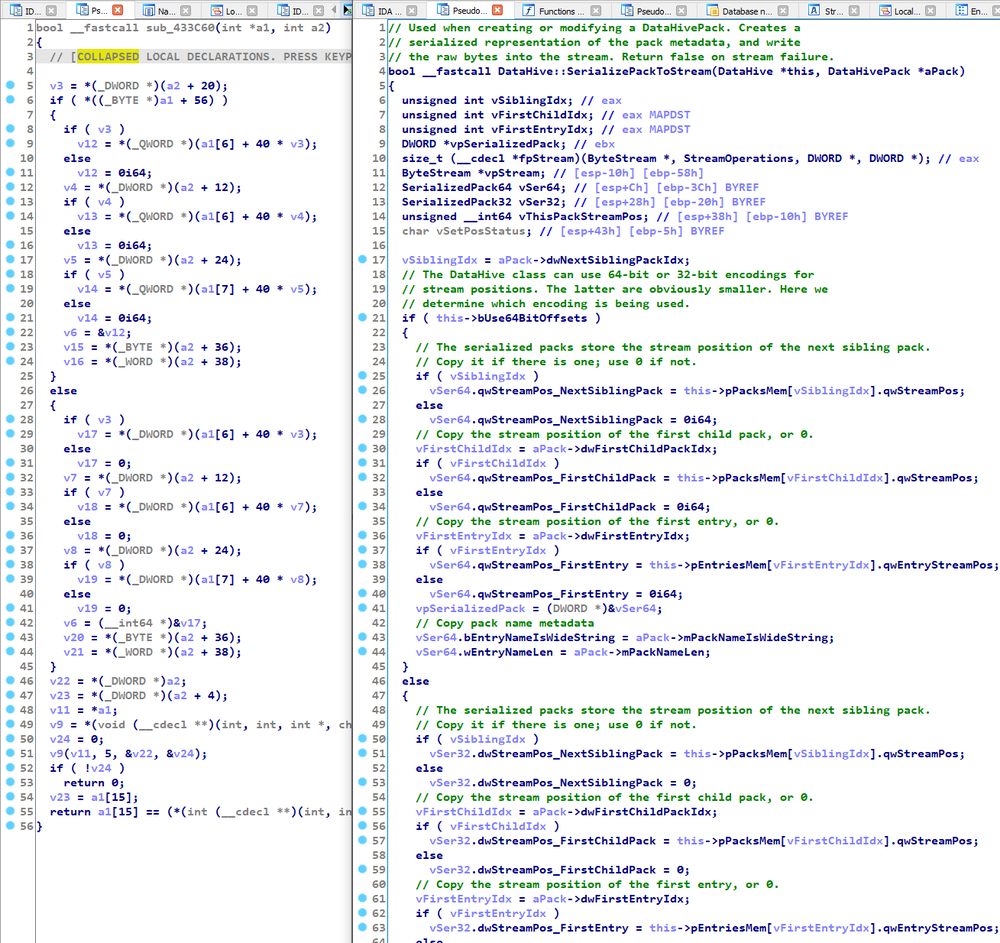 Next, IDA's function folders should make it easy to find the parts that interest you:
Next, IDA's function folders should make it easy to find the parts that interest you:
|
Malware | |||
| 2020-09-01 16:45:00 | An Exhaustively-Analyzed IDB for ComRAT v4 (lien direct) | This blog entry announces the release of an exhaustive analysis of ComRAT v4. You can find the IDBs here.More specifically, an IDB for the sample with hash 0139818441431C72A1935E7F740A1CC458A63452, which was mentioned in the ESET report (see especially its attached PDF), and which is available online on Hybrid Analysis. All of the analysis has been performed in Hex-Rays 64-bit, so the results will be less interesting to IDA users who do not own Hex-Rays 64-bit. That is to say, if you open the IDB, you should definitely use Hex-Rays to view the function decompilations, as that is where all of the naming and commenting has taken place. It is rich with detail, in comparison to the disassembly listing's barrenness.This analysis took roughly six weeks of full-time work. I have spent the pandemic working on a new training class on C++ reverse engineering; part of the preparation includes large-scale analysis of C++ programs. As such, ESET's report of ComRAT's use of C++ caught my eye. ComRAT has a beautiful architecture, and many sophisticated components, all of which I believe deserve a detailed report unto themselves. I had begun writing such a report, but decided that it was side-tracking me from my ultimate goals with my new training class. Hence, I had decided to wait until the class was ready, and release a collection of reports on the software architectures of C++ malware families (perhaps as a book) after I was done. Thus, my write-up on ComRAT's architecture will have to wait. You can consider this release, instead, as a supplement to the ESET report. (Note that if you are interested in the forthcoming C++ training class, it probably will not be available for roughly another year. More generally, remote public classes (where individual students can sign up) are temporarily suspended; remote private classes (multiple students on behalf of the same organization) are currently available. If you would like to be notified when public classes become available, or when the C++ course is ready, please sign up on our no-spam, very low-volume, course notification mailing list. (Click the button that says "Provide your email to be notified of public course availability".) )(Note also that I have more analyses like this waiting to be released. FlawedGrace and XAgent are ready; Kelihos is in progress. If you can provide me with a bundle of Careto SGH samples, preferably Windows 64-bit, please get in touch.)About the AnalysisThis analysis was conducted purely statically, without access to RTTI, or any other form of debug information. The only external information I had was the ESET report. I have reverse engineered every function in the binary that is not part of the C++ standard library, and some of those that are. To get an idea of what the sample looks like before and after analysis, here's a screenshot of the binary freshly loaded into IDA on the left, versus the analyzed one on the right. See if you can spot the difference: | Malware | |||
| 2020-05-08 01:22:33 | A Compiler Optimization involving Speculative Execution of Function Pointers (lien direct) | Today I discovered a neat optimization that I'd only heard about in graduate school, but had never seen in a real binary. Although the code below involves virtual functions in C++, the same technique would work for ordinary function pointers in C. A few other optimizations are referenced in the explanation below; all of them can be found in my presentation, "Compiler Optimizations for Reverse Engineers", which is the course sample for one of my reverse engineering training classes.The optimization has to do with increasing speculative execution performance for function pointers that nearly always target one particular destination. Note that this is in contrast to the compiler optimization known as "devirtualization", which is when a compiler can prove that a particular function pointer invocation must always target one particular location, and turns the indirect call into a direct one. The optimization described in this entry differs in that the function pointer might nearly always point to one location, but might occasionally point elsewhere. (These estimates of runtime behavior could be derived through profiling, for example.) The following is a snippet of code that comes from Microsoft's Active Template Library (ATL). More specifically, the smart pointer known as CComPtr, held in atlcomcli.h. Here is the code; modest, and unassuming: template class CComPtr { T* p; // Release the interface and set to NULL void Release() throw() { T* pTemp = p; if (pTemp) { p = NULL; pTemp->Release(); } } }Being a template class library, the programmer is free to create their own classes based on CComPtr by specifying any class type for the template typename parameter T. Or rather, any class type that has a method named "Release" with signature "void Release()", as that function is invoked by the if-body in the code above. In this scenario, Release is a virtual function - that is to say, objects of type T contain a function pointer pointing to the implementation of a function called “void Release()”.In the code below, T is specialized by (i.e., replaced with) a scary-looking ATL type name called ATL::CComObject. So in particular, here is the compiled version of CComPtr::Release, whose generic C++ code was shown above. The first four lines aren't interesting: .text:18005121B mov rcx, [rcx] ; T* pTemp = p; .text:18005121E test rcx, rcx ; if (pTemp) { .text:180051221 jz short return ; [if not taken, return] .text:180051223 and qword ptr [rax], 0 ; p = NULL;The final line, the call to pTemp->Release, has a longer compiled body than one might expect. A line-by-line explanation follows below. .text:180051227 lea rdx, offset ATL::CComObject::Release .text:18005122E mov rax, [rcx] .text:180051231 mov rax, [rax+10h] ; rax now contains the pTemp->Release pointer .text:180051235 cmp rax, rdx ; did rax match the fixed location in rdx above? .text:180051238 jnz short no_match .text:18005123A call ATL::CComObject::Release .text:18005123F .text:18005123F return: .text:18005123F add rsp, 28h .text:180051243 retn .text:180051244 .text:180051244 no_match: .text:180051244 add rsp, 28h .text:180051248 jmp raxTo explain the code above: Line #-27: move the offset some specific function into rdx.Line #-2E through -31: rax now contains the pTemp->Release function pointer.Line #-35 through -38: Compare rax and rdx. If equal, don't take the jump.Line #- |
1
We have: 7 articles.
We have: 7 articles.
To see everything:
Our RSS (filtrered)
