What's new arround internet
| Src | Date (GMT) | Titre | Description | Tags | Stories | Notes |
| 2018-04-16 07:42:52 | My letter urging Georgia governor to veto anti-hacking bill (lien direct) | February 16, 2018Office of the Governor206 Washington Street111 State CapitolAtlanta, Georgia 30334Re: SB 315Dear Governor Deal:I am writing to urge you to veto SB315, the "Unauthorized Computer Access" bill.The cybersecurity community, of which Georgia is a leader, is nearly unanimous that SB315 will make cybersecurity worse. You've undoubtedly heard from many of us opposing this bill. It does not help in prosecuting foreign hackers who target Georgian computers, such as our elections systems. Instead, it prevents those who notice security flaws from pointing them out, thereby getting them fixed. This law violates the well-known Kirchhoff's Principle, that instead of secrecy and obscurity, that security is achieved through transparency and openness.That the bill contains this flaw is no accident. The justification for this bill comes from an incident where a security researcher noticed a Georgia state election system had made voter information public. This remained unfixed, months after the vulnerability was first disclosed, leaving the data exposed. Those in charge decided that it was better to prosecute those responsible for discovering the flaw rather than punish those who failed to secure Georgia voter information, hence this law.Too many security experts oppose this bill for it to go forward. Signing this bill, one that is weak on cybersecurity by favoring political cover-up over the consensus of the cybersecurity community, will be part of your legacy. I urge you instead to veto this bill, commanding the legislature to write a better one, this time consulting experts, which due to Georgia's thriving cybersecurity community, we do not lack.Thank you for your attention.Sincerely,Robert Graham(formerly) Chief Scientist, Internet Security Systems | Guideline | |||
| 2018-04-15 21:57:11 | Let\'s stop talking about password strength (lien direct) |  Picture from EFF -- CC-BY licenseNear the top of most security recommendations is to use "strong passwords". We need to stop doing this.Yes, weak passwords can be a problem. If a website gets hacked, weak passwords are easier to crack. It's not that this is wrong advice.On the other hand, it's not particularly good advice, either. It's far down the list of important advice that people need to remember. "Weak passwords" are nowhere near the risk of "password reuse". When your Facebook or email account gets hacked, it's because you used the same password across many websites, not because you used a weak password.Important websites, where the strength of your password matters, already take care of the problem. They use strong, salted hashes on the backend to protect the password. On the frontend, they force passwords to be a certain length and a certain complexity. Maybe the better advice is to not trust any website that doesn't enforce stronger passwords (minimum of 8 characters consisting of both letters and non-letters).To some extent, this "strong password" advice has become obsolete. A decade ago, websites had poor protection (MD5 hashes) and no enforcement of complexity, so it was up to the user to choose strong passwords. Now that important websites have changed their behavior, such as using bcrypt, there is less onus on the user.But the real issue here is that "strong password" advice reflects the evil, authoritarian impulses of the infosec community. Instead of measuring insecurity in terms of costs vs. benefits, risks vs. rewards, we insist that it's an issue of moral weakness. We pretend that flaws happen because people are greedy, lazy, and ignorant. We pretend that security is its own goal, a benefit we should achieve, rather than a cost we must endure.We like giving moral advice because it's easy: just be "stronger". Discussing "password reuse" is more complicated, forcing us discuss password managers, writing down passwords on paper, that it's okay to reuse passwords for crappy websites you don't care about, and so on.What I'm trying to say is that the moral weakness here is us. Rather then give pertinent advice we give lazy advice. We give the advice that victim shames them for being weak while pretending that we are strong.So stop telling people to use strong passwords. It's crass advice on your part and largely unhelpful for your audience, distracting them from the more important things. Picture from EFF -- CC-BY licenseNear the top of most security recommendations is to use "strong passwords". We need to stop doing this.Yes, weak passwords can be a problem. If a website gets hacked, weak passwords are easier to crack. It's not that this is wrong advice.On the other hand, it's not particularly good advice, either. It's far down the list of important advice that people need to remember. "Weak passwords" are nowhere near the risk of "password reuse". When your Facebook or email account gets hacked, it's because you used the same password across many websites, not because you used a weak password.Important websites, where the strength of your password matters, already take care of the problem. They use strong, salted hashes on the backend to protect the password. On the frontend, they force passwords to be a certain length and a certain complexity. Maybe the better advice is to not trust any website that doesn't enforce stronger passwords (minimum of 8 characters consisting of both letters and non-letters).To some extent, this "strong password" advice has become obsolete. A decade ago, websites had poor protection (MD5 hashes) and no enforcement of complexity, so it was up to the user to choose strong passwords. Now that important websites have changed their behavior, such as using bcrypt, there is less onus on the user.But the real issue here is that "strong password" advice reflects the evil, authoritarian impulses of the infosec community. Instead of measuring insecurity in terms of costs vs. benefits, risks vs. rewards, we insist that it's an issue of moral weakness. We pretend that flaws happen because people are greedy, lazy, and ignorant. We pretend that security is its own goal, a benefit we should achieve, rather than a cost we must endure.We like giving moral advice because it's easy: just be "stronger". Discussing "password reuse" is more complicated, forcing us discuss password managers, writing down passwords on paper, that it's okay to reuse passwords for crappy websites you don't care about, and so on.What I'm trying to say is that the moral weakness here is us. Rather then give pertinent advice we give lazy advice. We give the advice that victim shames them for being weak while pretending that we are strong.So stop telling people to use strong passwords. It's crass advice on your part and largely unhelpful for your audience, distracting them from the more important things. |
||||
| 2018-04-01 22:59:06 | Why the crypto-backdoor side is morally corrupt (lien direct) | Crypto-backdoors for law enforcement is a reasonable position, but the side that argues for it adds things that are either outright lies or morally corrupt. Every year, the amount of digital evidence law enforcement has to solve crimes increases, yet they outrageously lie, claiming they are "going dark", losing access to evidence. A weirder claim is that those who oppose crypto-backdoors are nonetheless ethically required to make them work. This is morally corrupt.That's the point of this Lawfare post, which claims:What I am saying is that those arguing that we should reject third-party access out of hand haven't carried their research burden. ... There are two reasons why I think there hasn't been enough research to establish the no-third-party access position. First, research in this area is “taboo” among security researchers. ... the second reason why I believe more research needs to be done: the fact that prominent non-government experts are publicly willing to try to build secure third-party-access solutions should make the information-security community question the consensus view. This is nonsense. It's like claiming we haven't cured the common cold because researchers haven't spent enough effort at it. When researchers claim they've tried 10,000 ways to make something work, it's like insisting they haven't done enough because they haven't tried 10,001 times.Certainly, half the community doesn't want to make such things work. Any solution for the "legitimate" law enforcement of the United States means a solution for illegitimate states like China and Russia which would use the feature to oppress their own people. Even if I believe it's a net benefit to the United States, I would never attempt such research because of China and Russia.But computer scientists notoriously ignore ethics in pursuit of developing technology. That describes the other half of the crypto community who would gladly work on the problem. The reason they haven't come up with solutions is because the problem is hard, really hard.The second reason the above argument is wrong: it says we should believe a solution is possible because some outsiders are willing to try. But as Yoda says, do or do not, there is no try. Our opinions on the difficulty of the problem don't change simply because people are trying. Our opinions change when people are succeeding. People are always trying the impossible, that's not evidence it's possible.The paper cherry picks things, like Intel CPU features, to make it seem like they are making forward progress. No. Intel's SGX extensions are there for other reasons. Sure, it's a new development, and new developments may change our opinion on the feasibility of law enforcement backdoors. But nowhere in talking about this new development have they actually proposes a solution to the backdoor problem. New developments happen all the time, and the pro-backdoor side is going to seize upon each and every one to claim that this, finally, solves the backdoor problem, without showing exactly how it solves the problem.The Lawfare post does make one good argument, that there is no such thing as "absolute security", and thus the argument is stupid that "crypto-backdoors would be less than absolute security". Too often in the cybersecurity community we reject solutions that don't provide "absolute security" while failing to acknowledge that "absolute security" is impossible.But that's not really what's going on here. Cryptographers aren't certain we've achieved even "adequate security" with current crypto regimes like SSL/TLS/HTTPS. Every few years we find horrible flaws in the old versions and have to develop new versions. | ||||
| 2018-03-29 22:25:24 | WannaCry after one year (lien direct) | In the news, Boeing (an aircraft maker) has been "targeted by a WannaCry virus attack". Phrased this way, it's implausible. There are no new attacks targeting people with WannaCry. There is either no WannaCry, or it's simply a continuation of the attack from a year ago.It's possible what happened is that an anti-virus product called a new virus "WannaCry". Virus families are often related, and sometimes a distant relative gets called the same thing. I know this watching the way various anti-virus products label my own software, which isn't a virus, but which virus writers often include with their own stuff. The Lazarus group, which is believed to be responsible for WannaCry, have whole virus families like this. Thus, just because an AV product claims you are infected with WannaCry doesn't mean it's the same thing that everyone else is calling WannaCry.Famously, WannaCry was the first virus/ransomware/worm that used the NSA ETERNALBLUE exploit. Other viruses have since added the exploit, and of course, hackers use it when attacking systems. It may be that a network intrusion detection system detected ETERNALBLUE, which people then assumed was due to WannaCry. It may actually have been an nPetya infection instead (nPetya was the second major virus/worm/ransomware to use the exploit).Or it could be the real WannaCry, but it's probably not a new "attack" that "targets" Boeing. Instead, it's likely a continuation from WannaCry's first appearance. WannaCry is a worm, which means it spreads automatically after it was launched, for years, without anybody in control. Infected machines still exist, unnoticed by their owners, attacking random machines on the Internet. If you plug in an unpatched computer onto the raw Internet, without the benefit of a firewall, it'll get infected within an hour.However, the Boeing manufacturing systems that were infected were not on the Internet, so what happened? The narrative from the news stories imply some nefarious hacker activity that "targeted" Boeing, but that's unlikely.We have now have over 15 years of experience with network worms getting into strange places disconnected and even "air gapped" from the Internet. The most common reason is laptops. Somebody takes their laptop to some place like an airport WiFi network, and gets infected. They put their laptop to sleep, then wake it again when they reach their destination, and plug it into the manufacturing network. At this point, the virus spreads and infects everything. This is especially the case with maintenance/support engineers, who often have specialized software they use to control manufacturing machines, for which they have a reason to connect to the local network even if it doesn't have useful access to the Internet. A single engineer may act as a sort of Typhoid Mary, going from customer to customer, infecting each in turn whenever they open their laptop.Another cause for infection is virtual machines. A common practice is to take "snapshots" of live machines and save them to backups. Should the virtual machine crash, instead of rebooting it, it's simply restored from the backed up running image. If that backup image is infected, then bringing it out of sleep will allow the worm to start spreading.Jake Williams claims he's seen three other manufacturing networks infected with WannaCry. Why does manufacturing seem more susceptible? The reason appears to be the "killswitch" that stops WannaCry from running elsewhere. The killswitch uses a DNS lookup, stopping itself if it can resolve a certain domain. Manufacturing networks are largely disconnected from the Internet enough that such DNS lookups don't work, so the domain can't be found, so the killswitch doesn't work. Thus, manufacturing systems are no more likely to get infected, but the lack of killswitch means the virus will conti | Medical | Wannacry APT 38 | ||
| 2018-03-12 05:46:00 | What John Oliver gets wrong about Bitcoin (lien direct) | John Oliver covered bitcoin/cryptocurrencies last night. I thought I'd describe a bunch of things he gets wrong. How Bitcoin worksNowhere in the show does it describe what Bitcoin is and how it works.Discussions should always start with Satoshi Nakamoto's original paper. The thing Satoshi points out is that there is an important cost to normal transactions, namely, the entire legal system designed to protect you against fraud, such as the way you can reverse the transactions on your credit card if it gets stolen. The point of Bitcoin is that there is no way to reverse a charge. A transaction is done via cryptography: to transfer money to me, you decrypt it with your secret key and encrypt it with mine, handing ownership over to me with no third party involved that can reverse the transaction, and essentially no overhead.All the rest of the stuff, like the decentralized blockchain and mining, is all about making that work.Bitcoin crazies forget about the original genesis of Bitcoin. For example, they talk about adding features to stop fraud, reversing transactions, and having a central authority that manages that. This misses the point, because the existing electronic banking system already does that, and does a better job at it than cryptocurrencies ever can. If you want to mock cryptocurrencies, talk about the "DAO", which did exactly that -- and collapsed in a big fraudulent scheme where insiders made money and outsiders didn't.Sticking to Satoshi's original ideas are a lot better than trying to repeat how the crazy fringe activists define Bitcoin.How does any money have value?Oliver's answer is currencies have value because people agree that they have value, like how they agree a Beanie Baby is worth $15,000.This is wrong. A better way of asking the question why the value of money changes. The dollar has been losing roughly 2% of its value each year for decades. This is called "inflation", as the dollar loses value, it takes more dollars to buy things, which means the price of things (in dollars) goes up, and employers have to pay us more dollars so that we can buy the same amount of things.The reason the value of the dollar changes is largely because the Federal Reserve manages the supply of dollars, though the same law of Supply and Demand. As you know, if a supply decreases (like oil), then the price goes up, or if the supply of something increases, the price goes down. The Fed manages money the same way: when prices rise (the dollar is worth less), the Fed reduces the supply of dollars, causing it to be worth more. Conversely, if prices fall (or don't rise fast enough), the Fed increases supply, so that the dollar is worth less.The reason money follows the law of Supply and Demand is because people use money, they consume it like they do other goods and services, like gasoline, tax preparation, food, dance lessons, and so forth. It's not line a fine art painting, a stamp collection or a Beanie Baby -- money is a product. It's just that people have a hard time thinking of it as a consumer product since, in their experience, money is what they use to buy consumer products. But it's a symmetric operation: when you buy gasoline with dollars, you are actually selling dollars in exchange for gasoline. That you call How Bitcoin worksNowhere in the show does it describe what Bitcoin is and how it works.Discussions should always start with Satoshi Nakamoto's original paper. The thing Satoshi points out is that there is an important cost to normal transactions, namely, the entire legal system designed to protect you against fraud, such as the way you can reverse the transactions on your credit card if it gets stolen. The point of Bitcoin is that there is no way to reverse a charge. A transaction is done via cryptography: to transfer money to me, you decrypt it with your secret key and encrypt it with mine, handing ownership over to me with no third party involved that can reverse the transaction, and essentially no overhead.All the rest of the stuff, like the decentralized blockchain and mining, is all about making that work.Bitcoin crazies forget about the original genesis of Bitcoin. For example, they talk about adding features to stop fraud, reversing transactions, and having a central authority that manages that. This misses the point, because the existing electronic banking system already does that, and does a better job at it than cryptocurrencies ever can. If you want to mock cryptocurrencies, talk about the "DAO", which did exactly that -- and collapsed in a big fraudulent scheme where insiders made money and outsiders didn't.Sticking to Satoshi's original ideas are a lot better than trying to repeat how the crazy fringe activists define Bitcoin.How does any money have value?Oliver's answer is currencies have value because people agree that they have value, like how they agree a Beanie Baby is worth $15,000.This is wrong. A better way of asking the question why the value of money changes. The dollar has been losing roughly 2% of its value each year for decades. This is called "inflation", as the dollar loses value, it takes more dollars to buy things, which means the price of things (in dollars) goes up, and employers have to pay us more dollars so that we can buy the same amount of things.The reason the value of the dollar changes is largely because the Federal Reserve manages the supply of dollars, though the same law of Supply and Demand. As you know, if a supply decreases (like oil), then the price goes up, or if the supply of something increases, the price goes down. The Fed manages money the same way: when prices rise (the dollar is worth less), the Fed reduces the supply of dollars, causing it to be worth more. Conversely, if prices fall (or don't rise fast enough), the Fed increases supply, so that the dollar is worth less.The reason money follows the law of Supply and Demand is because people use money, they consume it like they do other goods and services, like gasoline, tax preparation, food, dance lessons, and so forth. It's not line a fine art painting, a stamp collection or a Beanie Baby -- money is a product. It's just that people have a hard time thinking of it as a consumer product since, in their experience, money is what they use to buy consumer products. But it's a symmetric operation: when you buy gasoline with dollars, you are actually selling dollars in exchange for gasoline. That you call |
Guideline | |||
| 2018-03-08 06:57:20 | Some notes on memcached DDoS (lien direct) | I thought I'd write up some notes on the memcached DDoS. Specifically, I describe how many I found scanning the Internet with masscan, and how to use masscan as a killswitch to neuter the worst of the attacks.Test your serversI added code to my port scanner for this, then scanned the Internet:masscan 0.0.0.0/0 -pU:11211 --banners | grep memcachedThis example scans the entire Internet (/0). Replaced 0.0.0.0/0 with your address range (or ranges).This produces output that looks like this:Banner on port 11211/udp on 172.246.132.226: [memcached] uptime=230130 time=1520485357 version=1.4.13Banner on port 11211/udp on 89.110.149.218: [memcached] uptime=3935192 time=1520485363 version=1.4.17Banner on port 11211/udp on 172.246.132.226: [memcached] uptime=230130 time=1520485357 version=1.4.13Banner on port 11211/udp on 84.200.45.2: [memcached] uptime=399858 time=1520485362 version=1.4.20Banner on port 11211/udp on 5.1.66.2: [memcached] uptime=29429482 time=1520485363 version=1.4.20Banner on port 11211/udp on 103.248.253.112: [memcached] uptime=2879363 time=1520485366 version=1.2.6Banner on port 11211/udp on 193.240.236.171: [memcached] uptime=42083736 time=1520485365 version=1.4.13The "banners" check filters out those with valid memcached responses, so you don't get other stuff that isn't memcached. To filter this output further, use the 'cut' to grab just column 6:... | cut -d ' ' -f 6 | cut -d: -f1You often get multiple responses to just one query, so you'll want to sort/uniq the list:... | sort | uniqMy results from an Internet wide scanI got 15181 results (or roughly 15,000).People are using Shodan to find a list of memcached servers. They might be getting a lot results back that response to TCP instead of UDP. Only UDP can be used for the attack.Masscan as exploit scriptBTW, you can not only use masscan to find amplifiers, you can also use it to carry out the DDoS. Simply import the list of amplifier IP addresses, then spoof the source address as that of the target. All the responses will go back to the source address.masscan -iL amplifiers.txt -pU:11211 --spoof-ip --rate 100000I point this out to show how there's no magic in exploiting this. Numerous exploit scripts have been released, because it's so easy.Why memcached servers are vulnerableLike many servers, memcached listens to local IP address 127.0.0.1 for local administration. By listening only on the local IP address, remote people cannot talk to the server. | Guideline | |||
| 2018-03-01 04:22:06 | AskRob: Does Tor let government peek at vuln info? (lien direct) | On Twitter, somebody asked this question:@ErrataRob comments?- E. Harding🇸🇾, друг народа (anti-Russia=block) (@Enopoletus) March 1, 2018The question is about a blog post that claims Tor privately tips off the government about vulnerabilities, using as proof a "vulnerability" from October 2007 that wasn't made public until 2011.The tl;dr is that it's bunk. There was no vulnerability, it was a feature request. The details were already public. There was no spy agency involved, but the agency that does Voice of America, and which tries to protect activists under foreign repressive regimes.DiscussionThe issue is that Tor traffic looks like Tor traffic, making it easy to block/censor, or worse, identify users. Over the years, Tor has added features to make it look more and more like normal traffic, like the encrypted traffic used by Facebook, Google, and Apple. Tors improves this bit-by-bit over time, but short of actually piggybacking on website traffic, it will always leave some telltale signature.An example showing how we can distinguish Tor traffic is the packet below, from the latest version of the Tor server: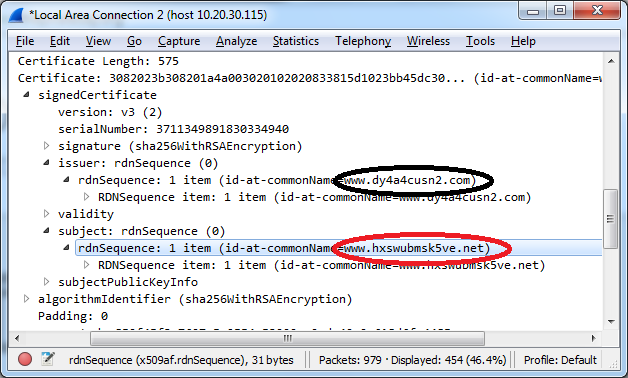 Had this been Google or Facebook, the names would be something like "www.google.com" or "facebook.com". Or, had this been a normal "self-signed" certificate, the names would still be recognizable. But Tor creates randomized names, with letters and numbers, making it distinctive. It's hard to automate detection of this, because it's only probably Tor (other self-signed certificates look like this, too), which means you'll have occasional "false-positives". But still, if you compare this to the pattern of traffic, you can reliably detect that Tor is happening on your network.This has always been a known issue, since the earliest days. Google the search term "detect tor traffic", and set your advanced search dates to before 2007, and you'll see lots of discussion about this, such as this post for writing intrusion-detection signatures for Tor.Among the things you'll find is this presentation from 2006 where its creator (Roger Dingledine) talks about how Tor can be identified on the network with its unique network fingerprint. For a "vulnerability" they supposedly kept private until 2011, they were awfully darn public about it. Had this been Google or Facebook, the names would be something like "www.google.com" or "facebook.com". Or, had this been a normal "self-signed" certificate, the names would still be recognizable. But Tor creates randomized names, with letters and numbers, making it distinctive. It's hard to automate detection of this, because it's only probably Tor (other self-signed certificates look like this, too), which means you'll have occasional "false-positives". But still, if you compare this to the pattern of traffic, you can reliably detect that Tor is happening on your network.This has always been a known issue, since the earliest days. Google the search term "detect tor traffic", and set your advanced search dates to before 2007, and you'll see lots of discussion about this, such as this post for writing intrusion-detection signatures for Tor.Among the things you'll find is this presentation from 2006 where its creator (Roger Dingledine) talks about how Tor can be identified on the network with its unique network fingerprint. For a "vulnerability" they supposedly kept private until 2011, they were awfully darn public about it. |
||||
| 2018-02-02 21:32:16 | Blame privacy activists for the Memo?? (lien direct) | Former FBI agent Asha Rangappa @AshaRangappa_ has a smart post debunking the Nunes Memo, then takes it all back again with an op-ed on the NYTimes blaming us privacy activists. She presents an obviously false narrative that the FBI and FISA courts are above suspicion.I know from first hand experience the FBI is corrupt. In 2007, they threatened me, trying to get me to cancel a talk that revealed security vulnerabilities in a large corporation's product. Such abuses occur because there is no transparency and oversight. FBI agents write down our conversation in their little notebooks instead of recording it, so that they can control the narrative of what happened, presenting their version of the converstion (leaving out the threats). In this day and age of recording devices, this is indefensible.She writes "I know firsthand that it's difficult to get a FISA warrant". Yes, the process was difficult for her, an underling, to get a FISA warrant. The process is different when a leader tries to do the same thing.I know this first hand having casually worked as an outsider with intelligence agencies. I saw two processes in place: one for the flunkies, and one for those above the system. The flunkies constantly complained about how there is too many process in place oppressing them, preventing them from getting their jobs done. The leaders understood the system and how to sidestep those processes.That's not to say the Nunes Memo has merit, but it does point out that privacy advocates have a point in wanting more oversight and transparency in such surveillance of American citizens.Blaming us privacy advocates isn't the way to go. It's not going to succeed in tarnishing us, but will push us more into Trump's camp, causing us to reiterate that we believe the FBI and FISA are corrupt. | Guideline | |||
| 2018-01-29 01:25:14 | The problematic Wannacry North Korea attribution (lien direct) | Last month, the US government officially "attributed" the Wannacry ransomware worm to North Korea. This attribution has three flaws, which are a good lesson for attribution in general.It was an accidentThe most important fact about Wannacry is that it was an accident. We've had 30 years of experience with Internet worms teaching us that worms are always accidents. While launching worms may be intentional, their effects cannot be predicted. While they appear to have targets, like Slammer against South Korea, or Witty against the Pentagon, further analysis shows this was just a random effect that was impossible to predict ahead of time. Only in hindsight are these effects explainable.We should hold those causing accidents accountable, too, but it's a different accountability. The U.S. has caused more civilian deaths in its War on Terror than the terrorists caused triggering that war. But we hold these to be morally different: the terrorists targeted the innocent, whereas the U.S. takes great pains to avoid civilian casualties. Since we are talking about blaming those responsible for accidents, we also must include the NSA in that mix. The NSA created, then allowed the release of, weaponized exploits. That's like accidentally dropping a load of unexploded bombs near a village. When those bombs are then used, those having lost the weapons are held guilty along with those using them. Yes, while we should blame the hacker who added ETERNAL BLUE to their ransomware, we should also blame the NSA for losing control of ETERNAL BLUE.A country and its assets are differentWas it North Korea, or hackers affilliated with North Korea? These aren't the same.North Korea doesn't really have hackers of its own. It doesn't have citizens who grow up with computers to pick from. Moreover, an internal hacking corps would create tainted citizens exposed to dangerous outside ideas.Instead, North Korea develops external hacking "assets", supporting several external hacking groups in China, Japan, and South Korea. This is similar to how intelligence agencies develop human "assets" in foreign countries. While these assets do things for their handlers, they also have normal day jobs, and do many things that are wholly independent and even sometimes against their handler's interests.For example, this Muckrock FOIA dump shows how "CIA assets" independently worked for Castro and assassinated a Panamanian president. That they also worked for the CIA does not make the CIA responsible for the Panamanian assassination.That CIA/intelligence assets work this way is well-known and uncontroversial. The fact that countries use hacker assets like this is the controversial part. These hackers do act independently, yet we refuse to consider this when we want to "attribute" attacks.Attribution is politicalWe have far better attribution for the nPetya attacks. It was less accidental (they clearly desired to disrupt Ukraine), and the hackers were much closer to the Russian government (Russian citizens). Yet, the Trump administration isn't fighting Russia, they are fighting North Korea, so they don't officially attribute nPetya to Russia, but do attribute Wannacry to North Korea.Trump is in conflict with North Korea. He is looking for ways to escalate the conflict. Attributing Wannacry helps achieve his political objectives.That it was blatantly politics is demonstrated by the | Wannacry | |||
| 2018-01-22 19:55:09 | "Skyfall attack" was attention seeking (lien direct) | After the Meltdown/Spectre attacks, somebody created a website promising related "Skyfall/Solace" attacks. They revealed today that it was a "hoax".It was a bad hoax. It wasn't a clever troll, parody, or commentary. It was childish behavior seeking attention.For all you hate naming of security vulnerabilities, Meltdown/Spectre was important enough to deserve a name. Sure, from an infosec perspective, it was minor, we just patch and move on. But from an operating-system and CPU design perspective, these things where huge.Page table isolation to fix Meltdown is a fundamental redesign of the operating system. What you learned in college about how Solaris, Windows, Linux, and BSD were designed is now out-of-date. It's on the same scale of change as address space randomization.The same is true of Spectre. It changes what capabilities are given to JavaScript (buffers and high resolution timers). It dramatically increases the paranoia we have of running untrusted code from the Internet. We've been cleansing JavaScript of things like buffer-overflows and type confusion errors, now we have to cleanse it of branch prediction issues.Moreover, not only do we need to change software, we need to change the CPU. No, we won't get rid of branch-prediction and out-of-order execution, but there things that can easily be done to mitigate these attacks. We won't be recalling the billions of CPUs already shipped, and it will take a year before fixed CPUs appear on the market, but it's still an important change. That we fix security through such a massive hardware change is by itself worthy of "names".Yes, the "naming" of vulnerabilities is annoying. A bunch of vulns named by their creators have disappeared, and we've stopped talking about them. On the other hand, we still talk about Heartbleed and Shellshock, because they were damn important. A decade from now, we'll still be talking about Meltdown/Spectre. Even if they hadn't been named by their creators, we still would've come up with nicknames to talk about them, because CVE numbers are so inconvenient.Thus, the hoax's mocking of the naming is invalid. It was largely incoherent rambling from somebody who really doesn't understand the importance of these vulns, who uses the hoax to promote themselves. | ||||
| 2018-01-04 02:29:18 | Some notes on Meltdown/Spectre (lien direct) | I thought I'd write up some notes.You don't have to worry if you patch. If you download the latest update from Microsoft, Apple, or Linux, then the problem is fixed for you and you don't have to worry. If you aren't up to date, then there's a lot of other nasties out there you should probably also be worrying about. I mention this because while this bug is big in the news, it's probably not news the average consumer needs to concern themselves with.This will force a redesign of CPUs and operating systems. While not a big news item for consumers, it's huge in the geek world. We'll need to redesign operating systems and how CPUs are made.Don't worry about the performance hit. Some, especially avid gamers, are concerned about the claims of "30%" performance reduction when applying the patch. That's only in some rare cases, so you shouldn't worry too much about it. As far as I can tell, 3D games aren't likely to see less than 1% performance degradation. If you imagine your game is suddenly slower after the patch, then something else broke it.This wasn't foreseeable. A common cliche is that such bugs happen because people don't take security seriously, or that they are taking "shortcuts". That's not the case here. Speculative execution and timing issues with caches are inherent issues with CPU hardware. "Fixing" this would make CPUs run ten times slower. Thus, while we can tweek hardware going forward, the larger change will be in software.There's no good way to disclose this. The cybersecurity industry has a process for coordinating the release of such bugs, which appears to have broken down. In truth, it didn't. Once Linus announced a security patch that would degrade performance of the Linux kernel, we knew the coming bug was going to be Big. Looking at the Linux patch, tracking backwards to the bug was only a matter of time. Hence, the release of this information was a bit sooner than some wanted. This is to be expected, and is nothing to be upset about.It helps to have a name. Many are offended by the crassness of naming vulnerabilities and giving them logos. On the other hand, we are going to be talking about these bugs for the next decade. Having a recognizable name, rather than a hard-to-remember number, is useful.Should I stop buying Intel? Intel has the worst of the bugs here. On the other hand, ARM and AMD alternatives have their own problems. Many want to deploy ARM servers in their data centers, but these are likely to expose bugs you don't see on x86 servers. The software fix, "page table isolation", seems to work, so there might not be anything to worry about. On the other hand, holding up purchases because of "fear" of this bug is a good way to squeeze price reductions out of your vendor. Conversely, later generation CPUs, "Haswell" and even "Skylake" seem to have the least performance degradation, so it might be time to upgrade older servers to newer processors.Intel misleads. Intel has a press release that implies they are not impacted any worse than others. This is wrong: the "Meltdown" issue appears to apply only to Intel CPUs. I don't like such marketing crap, so I mention it. Statements from companies:Amazon AWSARMAMDIntelAnders Fogh's negative result |
Guideline | |||
| 2018-01-03 22:45:31 | Why Meltdown exists (lien direct) | So I thought I'd answer this question. I'm not a "chipmaker", but I've been optimizing low-level assembly x86 assembly language for a couple of decades.I'd love a blogpost written from the perspective of a chipmaker - Why this issue exists. I'd never question their competency, but it seems like a violation of expectations in hindsight. Based on my very limited understanding of these issues.- SwiftOnSecurity (@SwiftOnSecurity) January 4, 2018The tl;dr version is this: the CPUs have no bug. The results are correct, it's just that the timing is different. CPU designers will never fix the general problem of undetermined timing.CPUs are deterministic in the results they produce. If you add 5+6, you always get 11 -- always. On the other hand, the amount of time they take is non-deterministic. Run a benchmark on your computer. Now run it again. The amount of time it took varies, for a lot of reasons.That CPUs take an unknown amount of time is an inherent problem in CPU design. Even if you do everything right, "interrupts" from clock timers and network cards will still cause undefined timing problems. Therefore, CPU designers have thrown the concept of "deterministic time" out the window.The biggest source of non-deterministic behavior is the high-speed memory cache on the chip. When a piece of data is in the cache, the CPU accesses it immediately. When it isn't, the CPU has to stop and wait for slow main memory. Other things happening in the system impacts the cache, unexpectedly evicting recently used data for one purpose in favor of data for another purpose.Hackers love "non-deterministic", because while such things are unknowable in theory, they are often knowable in practice.That's the case of the granddaddy of all hacker exploits, the "buffer overflow". From the programmer's perspective, the bug will result in just the software crashing for undefinable reasons. From the hacker's perspective, they reverse engineer what's going on underneath, then carefully craft buffer contents so the program doesn't crash, but instead continue to run the code the hacker supplies within the buffer. Buffer overflows are undefined in theory, well-defined in practice.Hackers have already been exploiting this defineable/undefinable timing problems with the cache for a long time. An example is cache timing attacks on AES. AES reads a matrix from memory as it encrypts things. By playing with the cache, evicting things, timing things, you can figure out the pattern of memory accesses, and hence the secret key.Such cache timing attacks have been around since the beginning, really, and it's simply an unsolvable problem. Instead, we have workarounds, such as changing our crypto algorithms to not depend upon cache, or better yet, implement them directly in the CPU (such as the Intel AES specialized instructions).What's happened today with Meltdown is that incompletely executed instructions, which discard their results, do affect the cache. We can then recover those partial/temporary/discarded results by measuring the cache timing. This has been known for a while, but we couldn't figure out how to successfully exploit this, as this paper from Anders Fogh reports. Hackers fixed this, making it practically exploitable.As a CPU des | ||||
| 2018-01-03 18:10:19 | Let\'s see if I\'ve got Metldown right (lien direct) | I thought I'd write down the proof-of-concept to see if I got it right.So the Meltdown paper lists the following steps: ; flush cache ; rcx = kernel address ; rbx = probe array retry: mov al, byte [rcx] shl rax, 0xc jz retry mov rbx, qword [rbx + rax] ; measure which of 256 cachelines were accessedSo the first step is to flush the cache, so that none of the 256 possible cache lines in our "probe array" are in the cache. There are many ways this can be done.Now pick a byte of secret kernel memory to read. Presumably, we'll just read all of memory, one byte at a time. The address of this byte is in rcx.Now execute the instruction: mov al, byte [rcx]This line of code will crash (raise an exception). That's because [rcx] points to secret kernel memory which we don't have permission to read. The value of the real al (the low-order byte of rax) will never actually change.But fear not! Intel is massively out-of-order. That means before the exception happens, it will provisionally and partially execute the following instructions. While Intel has only 16 visible registers, it actually has 100 real registers. It'll stick the result in a pseudo-rax register. Only at the end of the long execution change, if nothing bad happen, will pseudo-rax register become the visible rax register.But in the meantime, we can continue (with speculative execution) operate on pseudo-rax. Right now it contains a byte, so we need to make it bigger so that instead of referencing which byte it can now reference which cache-line. (This instruction multiplies by 4096 instead of just 64, to prevent the prefetcher from loading multiple adjacent cache-lines). shl rax, 0xcNow we use pseudo-rax to provisionally load the indicated bytes. mov rbx, qword [rbx + rax]Since we already crashed up top on the first instruction, these results will never be committed to rax and rbx. However, the cache will change. Intel will have provisionally loaded that cache-line into memory.At this point, it's simply a matter of stepping through all 256 cache-lines in order to find the one that's fast (already in the cache) where all the others are slow. | ||||
| 2017-12-19 21:59:49 | Bitcoin: In Crypto We Trust (lien direct) | Tim Wu, who coined "net neutrality", has written an op-ed on the New York Times called "The Bitcoin Boom: In Code We Trust". He is wrong is wrong about "code".The wrong "trust"Wu builds a big manifesto about how real-world institutions aren't can't be trusted. Certainly, this reflects the rhetoric from a vocal wing of Bitcoin fanatics, but it's not the Bitcoin manifesto.Instead, the word "trust" in the Bitcoin paper is much narrower, referring to how online merchants can't trust credit-cards (for example). When I bought school supplies for my niece when she studied in Canada, the online site wouldn't accept my U.S. credit card. They didn't trust my credit card. However, they trusted my Bitcoin, so I used that payment method instead, and succeeded in the purchase.Real-world currencies like dollars are tethered to the real-world, which means no single transaction can be trusted, because "they" (the credit-card company, the courts, etc.) may decide to reverse the transaction. The manifesto behind Bitcoin is that a transaction cannot be reversed -- and thus, can always be trusted.Deliberately confusing the micro-trust in a transaction and macro-trust in banks and governments is a sort of bait-and-switch.The wrong inspirationWu claims:"It was, after all, a carnival of human errors and misfeasance that inspired the invention of Bitcoin in 2009, namely, the financial crisis."Not true. Bitcoin did not appear fully formed out of the void, but was instead based upon a series of innovations that predate the financial crisis by a decade. Moreover, the financial crisis had little to do with "currency". The value of the dollar and other major currencies were essentially unscathed by the crisis. Certainly, enthusiasts looking backward like to cherry pick the financial crisis as yet one more reason why the offline world sucks, but it had little to do with Bitcoin.In crypto we trustIt's not in code that Bitcoin trusts, but in crypto. Satoshi makes that clear in one of his posts on the subject:A generation ago, multi-user time-sharing computer systems had a similar problem. Before strong encryption, users had to rely on password protection to secure their files, placing trust in the system administrator to keep their information private. Privacy could always be overridden by the admin based on his judgment call weighing the principle of privacy against other concerns, or at the behest of his superiors. Then strong encryption became available to the masses, and trust was no longer required. Data could be secured in a way that was physically impossible for others to access, no matter for what reason, no matter how good the excuse, no matter what.You don't possess Bitcoins. Instead, all the coins are on the public blockchain under your "address". What you possess is the secret, private key that matches the address. Transferring Bitcoin means using your private key to unlock your coins and transfer them to another. If you print out your private key on paper, and delete it from the computer, it can never be hacked.Trust is in this crypto operation. Trust is in your private crypto key.We don't trust the codeThe manifesto "in code we trust" has been proven wrong again and again. We don't trust computer code (software) in the cryptocurrency world.The most profound example is something known as the "DAO" on top of Ethereum, Bitcoin's major competitor. Ethereum allows "smart contracts" containing code. The quasi-religious manifesto of the DAO smart-contract is that the "code is the contract", that all the terms and conditions are specified within the smart-contract co | Uber | |||
| 2017-12-06 20:16:00 | Libertarians are against net neutrality (lien direct) | This post claims to be by a libertarian in support of net neutrality. As a libertarian, I need to debunk this. "Net neutrality" is a case of one-hand clapping, you rarely hear the competing side, and thus, that side may sound attractive. This post is about the other side, from a libertarian point of view.That post just repeats the common, and wrong, left-wing talking points. I mean, there might be a libertarian case for some broadband regulation, but this isn't it.This thing they call "net neutrality" is just left-wing politics masquerading as some sort of principle. It's no different than how people claim to be "pro-choice", yet demand forced vaccinations. Or, it's no different than how people claim to believe in "traditional marriage" even while they are on their third "traditional marriage".Properly defined, "net neutrality" means no discrimination of network traffic. But nobody wants that. A classic example is how most internet connections have faster download speeds than uploads. This discriminates against upload traffic, harming innovation in upload-centric applications like DropBox's cloud backup or BitTorrent's peer-to-peer file transfer. Yet activists never mention this, or other types of network traffic discrimination, because they no more care about "net neutrality" than Trump or Gingrich care about "traditional marriage".Instead, when people say "net neutrality", they mean "government regulation". It's the same old debate between who is the best steward of consumer interest: the free-market or government.Specifically, in the current debate, they are referring to the Obama-era FCC "Open Internet" order and reclassification of broadband under "Title II" so they can regulate it. Trump's FCC is putting broadband back to "Title I", which means the FCC can't regulate most of its "Open Internet" order.Don't be tricked into thinking the "Open Internet" order is anything but intensely politically. The premise behind the order is the Democrat's firm believe that it's government who created the Internet, and all innovation, advances, and investment ultimately come from the government. It sees ISPs as inherently deceitful entities who will only serve their own interests, at the expense of consumers, unless the FCC protects consumers.It says so right in the order itself. It starts with the premise that broadband ISPs are evil, using illegitimate "tactics" to hurt consumers, and continues with similar language throughout the order. A good contrast to this can be seen in Tim Wu's non-political original paper in 2003 that coined the term "net neutrality". Whereas the FCC sees broadband ISPs as enemies of consumers, Wu saw them as allies. His concern was not that ISPs would do evil things, but that they would do stupid things, such as favoring short-term interests over long-term innovation (such as having faster downloads than uploads).The political depravity of the FCC's order can be seen in this comment from one of the commissio A good contrast to this can be seen in Tim Wu's non-political original paper in 2003 that coined the term "net neutrality". Whereas the FCC sees broadband ISPs as enemies of consumers, Wu saw them as allies. His concern was not that ISPs would do evil things, but that they would do stupid things, such as favoring short-term interests over long-term innovation (such as having faster downloads than uploads).The political depravity of the FCC's order can be seen in this comment from one of the commissio |
||||
| 2017-11-24 03:02:11 | A Thanksgiving Carol: How Those Smart Engineers at Twitter Screwed Me (lien direct) | Thanksgiving Holiday is a time for family and cheer. Well, a time for family. It's the holiday where we ask our doctor relatives to look at that weird skin growth, and for our geek relatives to fix our computers. This tale is of such computer support, and how the "smart" engineers at Twitter have ruined this for life.My mom is smart, but not a good computer user. I get my enthusiasm for science and math from my mother, and she has no problem understanding the science of computers. She keeps up when I explain Bitcoin. But she has difficulty using computers. She has this emotional, irrational belief that computers are out to get her.This makes helping her difficult. Every problem is described in terms of what the computer did to her, not what she did to her computer. It's the computer that needs to be fixed, instead of the user. When I showed her the "haveibeenpwned.com" website (part of my tips for securing computers), it showed her Tumblr password had been hacked. She swore she never created a Tumblr account -- that somebody or something must have done it for her. Except, I was there five years ago and watched her create it.Another example is how GMail is deleting her emails for no reason, corrupting them, and changing the spelling of her words. She emails the way an impatient teenager texts -- all of us in the family know the misspellings are not GMail's fault. But I can't help her with this because she keeps her GMail inbox clean, deleting all her messages, leaving no evidence behind. She has only a vague description of the problem that I can't make sense of.This last March, I tried something to resolve this. I configured her GMail to send a copy of all incoming messages to a new, duplicate account on my own email server. With evidence in hand, I would then be able solve what's going on with her GMail. I'd be able to show her which steps she took, which buttons she clicked on, and what caused the weirdness she's seeing.Today, while the family was in a state of turkey-induced torpor, my mom brought up a problem with Twitter. She doesn't use Twitter, she doesn't have an account, but they keep sending tweets to her phone, about topics like Denzel Washington. And she said something about "peaches" I didn't understand.This is how the problem descriptions always start, chaotic, with mutually exclusive possibilities. If you don't use Twitter, you don't have the Twitter app installed, so how are you getting Tweets? Over much gnashing of teeth, it comes out that she's getting emails from Twitter, not tweets, about Denzel Washington -- to someone named "Peaches Graham". Naturally, she can only describe these emails, because she's already deleted them.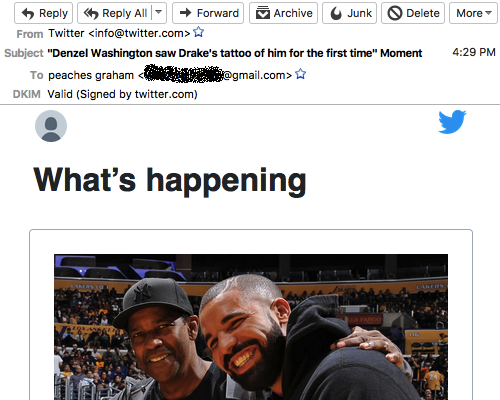 "Ah ha!", I think. I've got the evidence! I'll just log onto my duplicate email server, and grab the copies to prove to her it was something she did.I find she is indeed receiving such emails, called "Moments", about topics trending on Twitter. They are signed with "DKIM", proving they are legitimate rather than from a hacker or spammer. The only way that can happen is if my mother signed up for Twitter, despite her protestations that she didn't.I look further back and find that there were also confirmation messages involved. Back in August, she got a typical Twit "Ah ha!", I think. I've got the evidence! I'll just log onto my duplicate email server, and grab the copies to prove to her it was something she did.I find she is indeed receiving such emails, called "Moments", about topics trending on Twitter. They are signed with "DKIM", proving they are legitimate rather than from a hacker or spammer. The only way that can happen is if my mother signed up for Twitter, despite her protestations that she didn't.I look further back and find that there were also confirmation messages involved. Back in August, she got a typical Twit |
||||
| 2017-11-23 01:31:13 | Don Jr.: I\'ll bite (lien direct) | So Don Jr. tweets the following, which is an excellent troll. So I thought I'd bite. The reason is I just got through debunk Democrat claims about NetNeutrality, so it seems like a good time to balance things out and debunk Trump nonsense.The issue here is not which side is right. The issue here is whether you stand for truth, or whether you'll seize any factoid that appears to support your side, regardless of the truthfulness of it. The ACLU obviously chose falsehoods, as I documented. In the following tweet, Don Jr. does the same.It's a preview of the hyperpartisan debates are you are likely to have across the dinner table tomorrow, which each side trying to outdo the other in the false-hoods they'll claim.Need something to discuss over #Thanksgiving dinner? Try thisStock markets at all time highsLowest jobless claims since 736 TRILLION added to economy since Election1.5M fewer people on food stampsConsumer confidence through roof Lowest Unemployment rate in 17 years #maga- Donald Trump Jr. (@DonaldJTrumpJr) November 23, 2017What we see in this number is a steady trend of these statistics since the Great Recession, with no evidence in the graphs showing how Trump has influenced these numbers, one way or the other.Stock markets at all time highsThis is true, but it's obviously not due to Trump. The stock markers have been steadily rising since the Great Recession. Trump has done nothing substantive to change the market trajectory. Also, he hasn't inspired the market to change it's direction.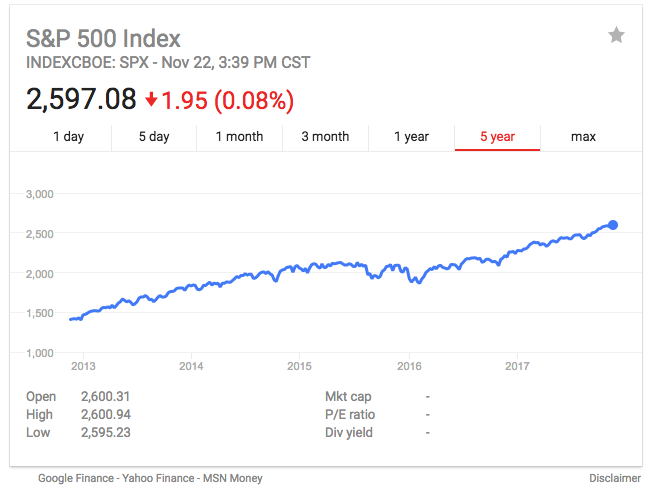 To be fair to Don Jr., we've all been crediting (or blaming) presidents for changes in the stock market despite the fact they have almost no influence over it. Presidents don't run the economy, it's an inappropriate conceit. The most influence they've had is in harming it.Lowest jobless claims since 73Again, let's graph this: To be fair to Don Jr., we've all been crediting (or blaming) presidents for changes in the stock market despite the fact they have almost no influence over it. Presidents don't run the economy, it's an inappropriate conceit. The most influence they've had is in harming it.Lowest jobless claims since 73Again, let's graph this: As we can see, jobless claims have been on a smooth downward trajectory since the Great Recession. It's difficult to see here how President Trump has influenced these numbers.6 Trillion added to the economyWhat he's referring to is that assets have risen in value, like the stock market, homes, gold, and even Bitcoin.But this is a well known fallacy known as Mercantilism, believing the "economy" is measure As we can see, jobless claims have been on a smooth downward trajectory since the Great Recession. It's difficult to see here how President Trump has influenced these numbers.6 Trillion added to the economyWhat he's referring to is that assets have risen in value, like the stock market, homes, gold, and even Bitcoin.But this is a well known fallacy known as Mercantilism, believing the "economy" is measure |
Uber | |||
| 2017-11-22 17:44:26 | NetNeutrality vs. limiting FaceTime (lien direct) | In response to my tweets/blogs against NetNeutrality, people have asked: what about these items? In this post, I debunk the fourth item.The FCC plans to completely repeal #NetNeutrality this week. Here's the censorship of speech that actually happened without Net Neutrality rules:#SaveNetNeutrality pic.twitter.com/6R29dajt44- Christian J. (@dtxErgaOmnes) November 22, 2017The issue the fourth item addresses is how AT&T restrict the use of Apple's FaceTime on its network back in 2012. This seems a clear NetNeutrality issue.But here's the thing: the FCC allowed these restrictions, despite the FCC's "Open Internet" order forbidding such things. In other words, despite the graphic's claims it "happened without net neutrality rules", the opposite is true, it happened with net neutrality rules.The FCC explains why they allowed it in their own case study on the matter. The short version is this: AT&T's network couldn't handle the traffic, so it was appropriate to restrict it until some time in the future (the LTE rollout) until it could. The issue wasn't that AT&T was restricting FaceTime in favor of its own video-calling service (it didn't have one), but it was instead an issue of "bandwidth management".When Apple released FaceTime, they themselves restricted it's use to WiFi, preventing its use on cell phone networks. That's because Apple recognized mobile networks couldn't handle it.When Apple flipped the switch and allowed it's use on mobile networks, because mobile networks had gotten faster, they clearly said "carrier restrictions may apply". In other words, it said "carriers may restrict FaceTime with our blessing if they can't handle the load".When Tim Wu wrote his paper defining "NetNeutrality" in 2003, he anticipated just this scenario. He wrote:"The goal of bandwidth management is, at a general level, aligned with network neutrality."He doesn't give "bandwidth management" a completely free pass. He mentions the issue frequently in his paper with a less favorable description, such as here:Similarly, while managing bandwidth is a laudable goal, its achievement through restricting certain application types is an unfortunate solution. The result is obviously a selective disadvantage for certain application markets. The less restrictive means is, as above, the technological management of bandwidth. Application-restrictions should, at best, be a stopgap solution to the problem of competing bandwidth demands. And that's what AT&T's FaceTime limiting was: an unfortunate stopgap solution until LTE was more fully deployed, which is fully allowed under Tim Wu's principle of NetNeutrality.So the ACLU's claim above is fully debunked: such things did happen even with NetNeutrality rules in place, and should happen. | ||||
| 2017-11-22 16:51:22 | NetNeutrality vs. Verizon censoring Naral (lien direct) | In response to my anti-NetNeutrality blogs/tweets, people ask what about this? In this post, I address the second question.The FCC plans to completely repeal #NetNeutrality this week. Here's the censorship of speech that actually happened without Net Neutrality rules:#SaveNetNeutrality pic.twitter.com/6R29dajt44- Christian J. (@dtxErgaOmnes) November 22, 2017Firstly, it's not a NetNeutrality issue (which applies only to the Internet), but an issue with text-messages. In other words, it's something that will continue to happen even with NetNeutrality rules. People relate this to NetNeutrality as an analogy, not because it actually is such an issue.Secondly, it's an edge/content issue, not a transit issue. The details in this case is that Verizon provides a program for sending bulk messages to its customers from the edge of the network. Verizon isn't censoring text messages in transit, but from the edge. You can send a text message to your friend on the Verizon network, and it won't be censored. Thus the analogy is incorrect -- the correct analogy would be with content providers like Twitter and Facebook, not ISPs like Comcast.Like all cell phone vendors, Verizon polices this content, canceling accounts that abuse the system, like spammers. We all agree such censorship is a good thing, and that such censorship of content providers is not remotely a NetNeutrality issue. Content providers do this not because they disapprove of the content of spam such much as the distaste their customers have for spam.Content providers that are political, rather than neutral to politics is indeed worrisome. It's not a NetNeutrality issue per se, but it is a general "neutrality" issue. We free-speech activists want all content providers (Twitter, Facebook, Verizon mass-texting programs) to be free of political censorship -- though we don't want government to mandate such neutrality.But even here, Verizon may be off the hook. They appear not be to be censoring one political view over another, but the controversial/unsavory way Naral expresses its views. Presumably, Verizon would be okay with less controversial political content.In other words, as Verizon expresses it's principles, it wants to block content that drivers away customers, but is otherwise neutral to the content. While this may unfairly target controversial political content, it's at least basically neutral.So in conclusion, while activists portray this as a NetNeutrality issue, it isn't. It's not even close. | ||||
| 2017-11-22 16:43:08 | NetNeutrality vs. AT&T censoring Pearl Jam (lien direct) | So in response to my anti-netneutrality tweets/blogs, Jose Pagliery asks "what about this?"The FCC plans to completely repeal #NetNeutrality this week. Here's the censorship of speech that actually happened without Net Neutrality rules:#SaveNetNeutrality pic.twitter.com/6R29dajt44- Christian J. (@dtxErgaOmnes) November 22, 2017Let's pick the first one. You can read about the details by Googling "AT&T Pearl Jam".First of all, this obviously isn't a Net Neutrality case. The case isn't about AT&T acting as an ISP transiting network traffic. Instead, this was about AT&T being a content provider, through their "Blue Room" subsidiary, whose content traveled across other ISPs. Such things will continue to happen regardless of the most stringent enforcement of NetNeutrality rules, since the FCC doesn't regulate content providers.Second of all, it wasn't AT&T who censored the traffic. It wasn't their Blue Room subsidiary who censored the traffic. It was a third party company they hired to bleep things like swear words and nipple slips. You are blaming AT&T for a decision by a third party that went against AT&T's wishes. It was an accident, not AT&T policy.Thirdly, and this is the funny bit, Tim Wu, the guy who defined the term "net neutrality", recently wrote an op-ed claiming that while ISPs shouldn't censor traffic, that content providers should. In other words, he argues that companies AT&T's Blue Room should censor political content.What activists like ACLU say about NetNeutrality have as little relationship to the truth as Trump's tweets. Both pick "facts" that agree with them only so long as you don't look into them. | ||||
| 2017-11-22 15:19:41 | The FCC has never defended Net Neutrality (lien direct) | This op-ed by a "net neutrality expert" claims the FCC has always defended "net neutrality". It's garbage.This wrong on its face. It imagines decades ago that the FCC inshrined some plaque on the wall stating principles that subsequent FCC commissioners have diligently followed. The opposite is true. FCC commissioners are a chaotic bunch, with different interests, influenced (i.e. "lobbied" or "bribed") by different telecommunications/Internet companies. Rather than following a principle, their Internet regulatory actions have been ad hoc and arbitrary -- for decades.Sure, you can cherry pick some of those regulatory actions as fitting a "net neutrality" narrative, but most actions don't fit that narrative, and there have been gross net neutrality violations that the FCC has ignored.There are gross violations going on right now that the FCC is allowing. Most egregiously is the "zero-rating" of video traffic on T-Mobile. This is a clear violation of the principles of net neutrality, yet the FCC is allowing it -- despite official "net neutrality" rules in place.The op-ed above claims that "this [net neutrality] principle was built into the architecture of the Internet". The opposite is true. Traffic discrimination was built into the architecture since the beginning. If you don't believe me, read RFC 791 and the "precedence" field.More concretely, from the beginning of the Internet as we know it (the 1990s), CDNs (content delivery networks) have provided a fast-lane for customers willing to pay for it. These CDNs are so important that the Internet wouldn't work without them.I just traced the route of my CNN live stream. It comes from a server 5 miles away, instead of CNN's headquarters 2500 miles away. That server is located inside Comcast's network, because CNN pays Comcast a lot of money to get a fast-lane to Comcast's customers.The reason these egregious net net violations exist is because it's in the interests of customers. Moving content closer to customers helps. Re-prioritizing (and charging less for) high-bandwidth video over cell networks helps customers.You might say it's okay that the FCC bends net neutrality rules when it benefits consumers, but that's garbage. Net neutrality claims these principles are sacred and should never be violated. Obviously, that's not true -- they should be violated when it benefits consumers. This means what net neutrality is really saying is that ISPs can't be trusted to allows act to benefit consumers, and therefore need government oversight. Well, if that's your principle, then what you are really saying is that you are a left-winger, not that you believe in net neutrality.Anyway, my point is that the above op-ed cherry picks a few data points in order to build a narrative that the FCC has always regulated net neutrality. A larger view is that the FCC has never defended this on principle, and is indeed, not defending it right now, even with "net neutrality" rules officially in place. | ||||
| 2017-11-21 16:38:17 | Your Holiday Cybersecurity Guide (lien direct) | Many of us are visiting parents/relatives this Thanksgiving/Christmas, and will have an opportunity to help our them with cybersecurity issues. I thought I'd write up a quick guide of the most important things.1. Stop them from reusing passwordsBy far the biggest threat to average people is that they re-use the same password across many websites, so that when one website gets hacked, all their accounts get hacked.To demonstrate the problem, go to haveibeenpwned.com and enter the email address of your relatives. This will show them a number of sites where their password has already been stolen, like LinkedIn, Adobe, etc. That should convince them of the severity of the problem.They don't need a separate password for every site. You don't care about the majority of website whether you get hacked. Use a common password for all the meaningless sites. You only need unique passwords for important accounts, like email, Facebook, and Twitter.Write down passwords and store them in a safe place. Sure, it's a common joke that people in offices write passwords on Post-It notes stuck on their monitors or under their keyboards. This is a common security mistake, but that's only because the office environment is widely accessible. Your home isn't, and there's plenty of places to store written passwords securely, such as in a home safe. Even if it's just a desk drawer, such passwords are safe from hackers, because they aren't on a computer.Write them down, with pen and paper. Don't put them in a MyPasswords.doc, because when a hacker breaks in, they'll easily find that document and easily hack your accounts.You might help them out with getting a password manager, or two-factor authentication (2FA). Good 2FA like YubiKey will stop a lot of phishing threats. But this is difficult technology to learn, and of course, you'll be on the hook for support issues, such as when they lose the device. Thus, while 2FA is best, I'm only recommending pen-and-paper to store passwords. (AccessNow has a guide, though I think YubiKey/U2F keys for Facebook and GMail are the best).2. Lock their phone (passcode, fingerprint, faceprint)You'll lose your phone at some point. It has the keys all all your accounts, like email and so on. With your email, phones thieves can then reset passwords on all your other accounts. Thus, it's incredibly important to lock the phone.Apple has made this especially easy with fingerprints (and now faceprints), so there's little excuse not to lock the phone.Note that Apple iPhones are the most secure. I give my mother my old iPhones so that they will have something secure.My mom demonstrates a problem you'll have with the older generation: she doesn't reliably have her phone with her, and charged. She's the opposite of my dad who religiously slaved to his phone. Even a small change to make her lock her phone means it'll be even more likely she won't have it with her when you need to call her.3. WiFi (WPA)Make sure their home WiFi is WPA encrypted. It probably already is, but it's worthwhile checking.The password should be written down on the same piece of paper as all the other passwords. This is importance. My parents just moved, Comcast installed a WiFi access point for them, and they promptly lost the piece of paper. When I wanted to debug some thing on their network today, they didn't know the password, and couldn't find the paper. Get that password written down in a place it won't get lost!Discourage them from extra security features like "SSID hiding" and/or "MAC address filtering". | ||||
| 2017-11-20 01:00:27 | Why Linus is right (as usual) (lien direct) | People are debating this email from Linus Torvalds (maintainer of the Linux kernel). It has strong language, like:Some security people have scoffed at me when I say that securityproblems are primarily "just bugs".Those security people are f*cking morons.Because honestly, the kind of security person who doesn't accept thatsecurity problems are primarily just bugs, I don't want to work with.I thought I'd explain why Linus is right.Linus has an unwritten manifesto of how the Linux kernel should be maintained. It's not written down in one place, instead we are supposed to reverse engineer it from his scathing emails, where he calls people morons for not understanding it. This is one such scathing email. The rules he's expressing here are:Large changes to the kernel should happen in small iterative steps, each one thoroughly debugged.Minor security concerns aren't major emergencies; they don't allow bypassing the rules more than any other bug/feature.Last year, some security "hardening" code was added to the kernel to prevent a class of buffer-overflow/out-of-bounds issues. This code didn't address any particular 0day vulnerability, but was designed to prevent a class of future potential exploits from being exploited. This is reasonable.This code had bugs, but that's no sin. All code has bugs.The sin, from Linus's point of view, is that when an overflow/out-of-bounds access was detected, the code would kill the user-mode process or kernel. Linus thinks it should have only generated warnings, and let the offending code continue to run.Of course, that would in theory make the change of little benefit, because it would no longer prevent 0days from being exploited.But warnings would only be temporary, the first step. There's likely to be be bugs in the large code change, and it would probably uncover bugs in other code. While bounds-checking is a security issue, it's first implementation will always find existing code having bounds bugs. Killing things made these bugs worse, causing catastrophic failures in the latest kernel that didn't exist before. Warnings, however, would have equally highlighted the bugs, but without causing catastrophic failures. My car runs multiple copies of Linux -- such catastrophic failures would risk my life.Only after a year, when the bugs have been fixed, would the default behavior of the code be changed to kill buggy code, thus preventing exploitation.In other words, large changes to the kernel should happen in small, manageable steps. This hardening hasn't existed for 25 years of the Linux kernel, so there's no emergency requiring it be added immediately rather than conservatively, no reason to bypass Linus's development processes. There's no reason it couldn't have been warnings for a year while working out problems, followed by killing buggy code later.Linus was correct here. No vuln has appeared in the last year that this code would've stopped, so the fact that it killed processes/kernels rather than generated warnings was unnecessary. Conversely, because it killed things, bugs in the kernel code were costly, and required emergency patches.Despite his unreasonable tone, Linus is a hugely reasonable person. He's not trying to stop changes to the kernel. He's not trying to stop security improvements. He's not even trying to stop processes from getting killed That's not why people are moronic. Instead, they are moronic for not understanding that large changes need to made conservatively, and security issues are no more important than any other | ||||
| 2017-11-17 17:55:29 | How to read newspapers (lien direct) | News articles don't contain the information you think. Instead, they are written according to a formula, and that formula is as much about distorting/hiding information as it is about revealing it.A good example is the following. I claimed hate-crimes aren't increasing. The tweet below tries to disprove me, by citing a news article that claims the opposite:Ugh turns out you're wrong! I know you let quality data inform your opinions, and hope the FBI is a sufficiently credible source for you https://t.co/SVwaLilF9B- Rune Sørensen (@runesoerensen) November 14, 2017But the data behind this article tells a very different story than the words.Every November, the FBI releases its hate-crime statistics for the previous year. They've been doing this every year for a long time. When they do so, various news organizations grab the data and write a quick story around it.By "story" I mean a story. Raw numbers don't interest people, so the writer instead has to wrap it in a narrative that does interest people. That's what the writer has done in the above story, leading with the fact that hate crimes have increased.But is this increase meaningful? What do the numbers actually say?To answer this, I went to the FBI's website, the source of this data, and grabbed the numbers for the last 20 years, and graphed them in Excel, producing the following graph: As you can see, there is no significant rise in hate-crimes. Indeed, the latest numbers are about 20% below the average for the last two decades, despite a tiny increase in the last couple years. Statistically/scientifically, there is no change, but you'll never read that in a news article, because it's boring and readers won't pay attention. You'll only get a "news story" that weaves a narrative that interests the reader.So back to the original tweet exchange. The person used the news story to disprove my claim, but going to the underlying data, it only supports my claim that the hate-crimes are going down, not up -- the small increases of the past couple years are insignificant to the larger decreases of the last two decades.So that's the point of this post: news stories are deceptive. You have to double-check the data they are based upon, and pay less attention to the narrative they weave, and even less attention to the title designed to grab your attention.Anyway, as a side-note, I'd like to apologize for being human. The snark/sarcasm of the tweet above gives me extra pleasure in proving them wrong :). As you can see, there is no significant rise in hate-crimes. Indeed, the latest numbers are about 20% below the average for the last two decades, despite a tiny increase in the last couple years. Statistically/scientifically, there is no change, but you'll never read that in a news article, because it's boring and readers won't pay attention. You'll only get a "news story" that weaves a narrative that interests the reader.So back to the original tweet exchange. The person used the news story to disprove my claim, but going to the underlying data, it only supports my claim that the hate-crimes are going down, not up -- the small increases of the past couple years are insignificant to the larger decreases of the last two decades.So that's the point of this post: news stories are deceptive. You have to double-check the data they are based upon, and pay less attention to the narrative they weave, and even less attention to the title designed to grab your attention.Anyway, as a side-note, I'd like to apologize for being human. The snark/sarcasm of the tweet above gives me extra pleasure in proving them wrong :). |
Guideline | |||
| 2017-10-25 19:26:43 | Some notes about the Kaspersky affair (lien direct) | I thought I'd write up some notes about Kaspersky, the Russian anti-virus vendor that many believe has ties to Russian intelligence.There's two angles to this story. One is whether the accusations are true. The second is the poor way the press has handled the story, with mainstream outlets like the New York Times more intent on pushing government propaganda than informing us what's going on.The pressBefore we address Kaspersky, we need to talk about how the press covers this.The mainstream media's stories have been pure government propaganda, like this one from the New York Times. It garbles the facts of what happened, and relies primarily on anonymous government sources that cannot be held accountable. It's so messed up that we can't easily challenge it because we aren't even sure exactly what it's claiming.The Society of Professional Journalists have a name for this abuse of anonymous sources, the "Washington Game". Journalists can identify this as bad journalism, but the big newspapers like The New York Times continues to do it anyway, because how dare anybody criticize them?For all that I hate the anti-American bias of The Intercept, at least they've had stories that de-garble what's going on, that explain things so that we can challenge them.Our GovernmentOur government can't tell us everything, of course. But at the same time, they need to tell us something, to at least being clear what their accusations are. These vague insinuations through the media hurt their credibility, not help it. The obvious craptitude is making us in the cybersecurity community come to Kaspersky's defense, which is not the government's aim at all.There are lots of issues involved here, but let's consider the major one insinuated by the NYTimes story, that Kaspersky was getting "data" files along with copies of suspected malware. This is troublesome if true.But, as Kaspersky claims today, it's because they had detected malware within a zip file, and uploaded the entire zip -- including the data files within the zip.This is reasonable. This is indeed how anti-virus generally works. It completely defeats the NYTimes insinuations.This isn't to say Kaspersky is telling the truth, of course, but that's not the point. The point is that we are getting vague propaganda from the government further garbled by the press, making Kaspersky's clear defense the credible party in the affair.It's certainly possible for Kaspersky to write signatures to look for strings like "TS//SI/OC/REL TO USA" that appear in secret US documents, then upload them to Russia. If that's what our government believes is happening, they need to come out and be explicit about it. They can easily setup honeypots, in the way described in today's story, to confirm it. However, it seems the government's description of honeypots is that Kaspersky only upload files that were clearly viruses, not data.KasperskyI believe Kaspersky is guilty, that the company and Eugene himself, works directly with Russian intelligence.That's because on a personal basis, people in government have given me specific, credible stories -- the sort of thing they should be making public. And these stories are who | ||||
| 2017-10-16 08:40:03 | Some notes on the KRACK attack (lien direct) | This is my interpretation of the KRACK attacks paper that describes a way of decrypting encrypted WiFi traffic with an active attack.tl;dr: Wow. Everyone needs to be afraid. It means in practice, attackers can decrypt a lot of wifi traffic, with varying levels of difficulty depending on your precise network setup. My post last July about the DEF CON network being safe was in error.DetailsThis is not a crypto bug but a protocol bug (a pretty obvious and trivial protocol bug).When a client connects to the network, the access-point will at some point send a random key to use for encryption. Because this packet may be lost in transmission, it can be repeated many times.What the hacker does is just repeatedly sends this packet, potentially hours later. Each time it does so, it resets the "keystream" back to the starting conditions. The obvious patch that device vendors will make is to only accept the first such packet it receives, ignore all the duplicates.At this point, the protocol bug becomes a crypto bug. We know how to break crypto when we have two keystreams from the same starting position. It's not always reliable, but reliable enough that people need to be afraid.Android, though, is the biggest danger. Rather than simply replaying the packet, a packet with a key of all zeroes can be sent. This allows attackers to setup a fake WiFi access-point and man-in-the-middle all traffic.In a related case, the access-point/base-station can sometimes also be attacked, affecting the stream sent to the client.Not only is sniffing possible, but in some limited cases, injection. This allows the traditional attack of adding bad code to the end of HTML pages in order to trick users into installing a virus.This is an active attack, not a passive attack, so in theory, it's detectable.Who is vulnerable?Everyone, pretty much.The hacker only needs to be within range of your WiFi. Your neighbor's teenage kid is going to be downloading and running the tool in order to eavesdrop on your packets.The hacker doesn't need to be logged into your network.It affects all WPA1/WPA2, the personal one with passwords that we use in home, and the enterprise version with certificates we use in enterprises.It can't defeat SSL/TLS or VPNs. Thus, if you feel your laptop is safe surfing the public WiFi at airports, then your laptop is still safe from this attack. With, with Android, it does allow running tools like sslstrip, which can fool many users.Your home network is vulnerable. Many devices will be using SSL/TLS, so are fine, like your Amazon echo, which you can continue to use without worrying about this attack. Other devices, like your Phillips lightbulbs, may not be so protected.How can I defend myself?Patch.More to the point, measure you current vendors by how long it takes them to patch. Throw away gear by those vendors that took a long time to patch and replace it with vendors that took a short time.High-end access-points that contains "WIPS" (WiFi Intrusion Prevention Systems) features should be able to detect this and block vulnerable clients from connecting to the network (once the vendor upgrades the systems, of course).At some point, you'll need to run the attack against yourself, to make sure all your devices are secure. Since you'll be constantly allowing random phones to connect to your network, you'll need to check th | ||||
| 2017-10-11 15:09:52 | "Responsible encryption" fallacies (lien direct) | Deputy Attorney General Rod Rosenstein gave a speech recently calling for "Responsible Encryption" (aka. "Crypto Backdoors"). It's full of dangerous ideas that need to be debunked.The importance of law enforcementThe first third of the speech talks about the importance of law enforcement, as if it's the only thing standing between us and chaos. It cites the 2016 Mirai attacks as an example of the chaos that will only get worse without stricter law enforcement.But the Mira case demonstrated the opposite, how law enforcement is not needed. They made no arrests in the case. A year later, they still haven't a clue who did it.Conversely, we technologists have fixed the major infrastructure issues. Specifically, those affected by the DNS outage have moved to multiple DNS providers, including a high-capacity DNS provider like Google and Amazon who can handle such large attacks easily.In other words, we the people fixed the major Mirai problem, and law-enforcement didn't.Moreover, instead being a solution to cyber threats, law enforcement has become a threat itself. The DNC didn't have the FBI investigate the attacks from Russia likely because they didn't want the FBI reading all their files, finding wrongdoing by the DNC. It's not that they did anything actually wrong, but it's more like that famous quote from Richelieu "Give me six words written by the most honest of men and I'll find something to hang him by". Give all your internal emails over to the FBI and I'm certain they'll find something to hang you by, if they want.Or consider the case of Andrew Auernheimer. He found AT&T's website made public user accounts of the first iPad, so he copied some down and posted them to a news site. AT&T had denied the problem, so making the problem public was the only want to force them to fix it. Such access to the website was legal, because AT&T had made the data public. However, prosecutors disagreed. In order to protect the powerful, they twisted and perverted the law to put Auernheimer in jail.It's not that law enforcement is bad, it's that it's not the unalloyed good Rosenstein imagines. When law enforcement becomes the thing Rosenstein describes, it means we live in a police state.Where law enforcement can't goRosenstein repeats the frequent claim in the encryption debate:Our society has never had a system where evidence of criminal wrongdoing was totally impervious to detectionOf course our society has places "impervious to detection", protected by both legal and natural barriers.An example of a legal barrier is how spouses can't be forced to testify against each other. This barrier is impervious.A better example, though, is how so much of government, intelligence, the military, and law enforcement itself is impervious. If prosecutors could gather evidence everywhere, then why isn't Rosenstein prosecuting those guilty of CIA torture?Oh, you say, government is a special exception. If that were the case, then why did Rosenstein dedicate a precious third of his speech discussing the "rule of law" and how it applies to everyone, "protecting people from abuse by the government". It obviously doesn't, there's one rule of government and a different rule for the people, and the rule for government means there's lots of places law enforcement can't go to gather evidence.Likewise, the crypto backdoor Rosenstein is demanding for citizens doesn't apply to the President, Congress, the NSA, the Army, or Rosenstein himself.Then there are the natural barriers. The police can't read your mind. They can only get the evidence that is there, like partial fingerprints, which are far less reliable than full fingerpri | Guideline | |||
| 2017-10-01 21:13:16 | Microcell through a mobile hotspot (lien direct) | I accidentally acquired a tree farm 20 minutes outside of town. For utilities, it gets electricity and basic phone. It doesn't get water, sewer, cable, or DSL (i.e. no Internet). Also, it doesn't really get cell phone service. While you can get SMS messages up there, you usually can't get a call connected, or hold a conversation if it does.We have found a solution -- an evil solution. We connect an AT&T "Microcell", which provides home cell phone service through your Internet connection, to an AT&T Mobile Hotspot, which provides an Internet connection through your cell phone service.Now, you may be laughing at this, because it's a circular connection. It's like trying to make a sailboat go by blowing on the sails, or lifting up a barrel to lighten the load in the boat.But it actually works.Since we get some, but not enough, cellular signal, we setup a mast 20 feet high with a directional antenna pointed to the cell tower 7.5 miles to the southwest, connected to a signal amplifier. It's still an imperfect solution, as we are still getting terrain distortions in the signal, but it provides a good enough signal-to-noise ratio to get a solid connection.We then connect that directional antenna directly to a high-end Mobile Hotspot. This gives us a solid 2mbps connection with a latency under 30milliseconds. This is far lower than the 50mbps you can get right next to a 4G/LTE tower, but it's still pretty good for our purposes.We then connect the AT&T Microcell to the Mobile Hotspot, via WiFi.To avoid the circular connection, we lock the frequencies for the Mobile Hotspot to 4G/LTE, and to 3G for the Microcell. This prevents the Mobile Hotspot locking onto the strong 3G signal from the Microcell. It also prevents the two from causing noise to the other.This works really great. We now get a strong cell signal on our phones even 400 feet from the house through some trees. We can be all over the property, out in the lake, down by the garden, and so on, and have our phones work as normal. It's only AT&T, but that's what the whole family uses.You might be asking why we didn't just use a normal signal amplifier, like they use on corporate campus. It boosts all the analog frequencies, making any cell phone service works.We've tried this, and it works a bit, allowing cell phones to work inside the house pretty well. But they don't work outside the house, which is where we spend a lot of time. In addition, while our newer phones work, my sister's iPhone 5 doesn't. We have no idea what's going on. Presumably, we could hire professional installers and stuff to get everything working, but nobody would quote us a price lower than $25,000 to even come look at the property.Another possible solution is satellite Internet. There are two satellites in orbit that cover the United States with small "spot beams" delivering high-speed service (25mbps downloads). However, the latency is 500milliseconds, which makes it impractical for low-latency applications like phone calls.While I know a lot about the technology in theory, I find myself hopelessly clueless in practice. I've been playing with SDR ("software defined radio") to try to figure out exactly where to locate and point the directional antenna, but I'm not sure I've come up with anything useful. In casual tests, it seems rotating the antenna from vertical to horizontal increases the signal-to-noise ratio a bit, which seems counter intuitive, and should not happen. So I'm completely lost.Anyway, I thought I'd write this up as a blogpost, in ca | ||||
| 2017-09-27 15:59:38 | Browser hacking for 280 character tweets (lien direct) | Twitter has raised the limit to 280 characters for a select number of people. However, they left open a hole, allowing anybody to make large tweets with a little bit of hacking. The hacking skills needed are basic hacking skills, which I thought I'd write up in a blog post.Specifically, the skills you will exercise are:basic command-line shellbasic HTTP requestsbasic browser DOM editingThe short instructionsThe basic instructions were found in tweets like the following:Click 'Tweet' in the web uiF12 Remove 'disable' on the tweet buttonClick it, and go to 'network', right click on the request and copy as cURLThen, add &weighted_character_count=true as a param to the end of the urlThen, resubmit the tweet with curl.Enjoy your 280 characters.- Christien Rioux âš› (@dildog) September 27, 2017These instructions are clear to the average hacker, but of course, a bit difficult for those learning hacking, hence this post.The command-line The basics of most hacking start with knowledge of the command-line. This is the "Terminal" app under macOS or cmd.exe under Windows. Almost always when you see hacking dramatized in the movies, they are using the command-line.In the beginning, the command-line is all computers had. To do anything on a computer, you had to type a "command" telling it what to do. What we see as the modern graphical screen is a layer on top of the command-line, one that translates clicks of the mouse into the raw commands.On most systems, the command-line is known as "bash". This is what you'll find on Linux and macOS. Windows historically has had a different command-line that uses slightly different syntax, though in the last couple years, they've also supported "bash". You'll have to install it first, such as by following these instructions.You'll see me use command that may not be yet installed on your "bash" command-line, like nc and curl. You'll need to run a command to install them, such as:sudo apt-get install nc curlThe thing to remember about the command-line is that the mouse doesn't work. You can't click to move the cursor as you normally do in applications. That's because the command-line predates the mouse by decades. Instead, you have to use arrow keys.I'm not going to spend much effort discussing the command-line, as a complete explanation is beyond the scope of this document. Instead, I'm assuming the reader either already knows it, or will learn-from-example as we go along.Web requestsThe basics of how the web works are really simple. A request to a web server is just a small packet of text, such as the following, which does a search on Google fo The basics of most hacking start with knowledge of the command-line. This is the "Terminal" app under macOS or cmd.exe under Windows. Almost always when you see hacking dramatized in the movies, they are using the command-line.In the beginning, the command-line is all computers had. To do anything on a computer, you had to type a "command" telling it what to do. What we see as the modern graphical screen is a layer on top of the command-line, one that translates clicks of the mouse into the raw commands.On most systems, the command-line is known as "bash". This is what you'll find on Linux and macOS. Windows historically has had a different command-line that uses slightly different syntax, though in the last couple years, they've also supported "bash". You'll have to install it first, such as by following these instructions.You'll see me use command that may not be yet installed on your "bash" command-line, like nc and curl. You'll need to run a command to install them, such as:sudo apt-get install nc curlThe thing to remember about the command-line is that the mouse doesn't work. You can't click to move the cursor as you normally do in applications. That's because the command-line predates the mouse by decades. Instead, you have to use arrow keys.I'm not going to spend much effort discussing the command-line, as a complete explanation is beyond the scope of this document. Instead, I'm assuming the reader either already knows it, or will learn-from-example as we go along.Web requestsThe basics of how the web works are really simple. A request to a web server is just a small packet of text, such as the following, which does a search on Google fo |
||||
| 2017-09-26 21:29:30 | 5 years with home NAS/RAID (lien direct) | I have lots of data-sets (packet-caps, internet-scans), so I need a large RAID system to hole it all. As I described in 2012, I bought a home "NAS" system. I thought I'd give the 5 year perspective.Reliability. I had two drives fail, which is about to be expected. Buying a new drive, swapping it in, and rebuilding the RAID went painless, though that's because I used RAID6 (two drive redundancy). RAID5 (one drive redundancy) is for chumps.Speed. I've been unhappy with the speed, but there's not much I can do about it. Mechanical drives access times are slow, and I don't see any way of fixing that.Cost. It's been $3000 over 5 years (including the two replacement drives). That comes out to $50/month. Amazon's "Glacier" service is $108/month. Since we all have the same hardware costs, it's unlikely that any online cloud storage can do better than doing it yourself.Moore's Law. For the same price as I spent 5 years ago, I can now get three times the storage, including faster processors in the NAS box. From that perspective, I've only spent $33/month on storage, as the remaining third still has value.Ease-of-use: The reason to go with a NAS is ease-of-use, so I don't have to mess with it. Yes, I'm a Linux sysadmin, but I have more than enough Linux boxen needing my attention. The NAS has been extremely easy to use, even dealing with the two disk failures.Battery backup. The cheap $50 CyberPower UPS I bought never worked well and completely failed recently, so I've ordered a $150 APC unit to replace it.Vendor. I chose Synology, and have no reason to complain. Of course they've had security vulnerabilities, but then, so have all their competition.DLNA. This is a standard for streaming music among home devices. It never worked well. I suspect partly it's Synology's fault that they can't transcode well. I suspect it's also the apps I tried on the iPad which have obvious problems. I end up streaming to the iPad by simply using the SMB protocol to serve files rather than a video protocol.Consumer vs. enterprise drives. I chose consumer rather than enterprise drives. I think this is always the best choice (RAID means inexpensive drives). But very smart people with experience in recovering data disagree with me.If you are in the market. If you are building your own NAS, get a 4 or 5 bay device and RAID6. Two-drive redundancy is really important. | ||||
| 2017-09-16 18:39:05 | People can\'t read (Equifax edition) (lien direct) | One of these days I'm going to write a guide for journalists reporting on the cyber. One of the items I'd stress is that they often fail to read the text of what is being said, but instead read some sort of subtext that wasn't explicitly said. This is valid sometimes -- as the subtext is what the writer intended all along, even if they didn't explicitly write it. Other times, though the imagined subtext is not what the writer intended at all.A good example is the recent Equifax breach. The original statement says:Equifax Inc. (NYSE: EFX) today announced a cybersecurity incident potentially impacting approximately 143 million U.S. consumers.The word consumers was widely translated to customers, as in this Bloomberg story:Equifax Inc. said its systems were struck by a cyberattack that may have affected about 143 million U.S. customers of the credit reporting agencyBut these aren't the same thing. Equifax is a credit rating agency, keeping data on people who are not its own customers. It's an important difference.Another good example is yesterday's quote "confirming" that the "Apache Struts" vulnerability was to blame:Equifax has been intensely investigating the scope of the intrusion with the assistance of a leading, independent cybersecurity firm to determine what information was accessed and who has been impacted. We know that criminals exploited a U.S. website application vulnerability. The vulnerability was Apache Struts CVE-2017-5638.But it doesn't confirm Struts was responsible. Blaming Struts is certainly the subtext of this paragraph, but it's not the text. It mentions that criminals had exploited the Struts vulnerability, but don't actually connect the dots to the breach we are all talking about.There's probably reasons for this. While it's easy for forensics to find evidence of Struts exploitation in logfiles, it's much harder to connect this to the breach. While they suspect Struts, they may not actually be able to confirm it. Or, maybe they are trying to cover things up, where they feel failing to patch is a lesser crime than what they really did.It's at this point journalists should earn their pay. Instead rewriting what they read on the Internet, they could do legwork and call up Equifax PR and ask.The purpose of this post isn't to discuss Equifax, but the tendency of people to "read between the lines", to read some subtext that wasn't actually expressed in the text. Sometimes the subtext is legitimately there, such as how Equifax clearly intends people to blame Struts thought they don't say it outright. Sometimes the subtext isn't there, such as how Equifax doesn't mean it's own customers, only "U.S. consumers". Journalists need to be careful about making assumptions about the subtext. Update: The Equifax CSO has a degree in music. Some people have criticized this. Most people have defended this, pointing out that almost nobody has an "infosec" degree in our industry, and many of the top people have no degree at all. Among others, @thegrugq has pointed out that infosec degrees are only a few years old -- they weren't around 20 years ago when today's corporate officers were getting their degrees.Again, we have the text/subtext problem, where people interpret infosec degrees as being the same as computer-science degrees, the later of which have existed for decades. Some, as in this case, consider them to be wildly different. Others consider them to be nearly the same. |
Guideline | Equifax | ||
| 2017-09-04 23:06:46 | State of MAC address randomization (lien direct) |  tldr: I went to DragonCon, a conference of 85,000 people, so sniff WiFi packets and test how many phones now uses MAC address randomization. Almost all iPhones nowadays do, but it seems only a third of Android phones do.Ten years ago at BlackHat, we presented the "data seepage" problem, how the broadcasts from your devices allow you to be tracked. Among the things we highlighted was how WiFi probes looking to connect to access-points expose the unique hardware address burned into the phone, the MAC address. This hardware address is unique to your phone, shared by no other device in the world. Evildoers, such as the NSA or GRU, could install passive listening devices in airports and train-stations around the world in order to track your movements. This could be done with $25 devices sprinkled around a few thousand places -- within the budget of not only a police state, but also the average hacker.In 2014, with the release of iOS 8, Apple addressed this problem by randomizing the MAC address. Every time you restart your phone, it picks a new, random, hardware address for connecting to WiFi. This causes a few problems: every time you restart your iOS devices, your home network sees a completely new device, which can fill up your router's connection table. Since that table usually has at least 100 entries, this shouldn't be a problem for your home, but corporations and other owners of big networks saw their connection tables suddenly get big with iOS 8.In 2015, Google added the feature to Android as well. However, even though most Android phones today support this feature in theory, it's usually not enabled.Recently, I went to DragonCon in order to test out how well this works. DragonCon is a huge sci-fi/fantasy conference in Atlanta in August, second to San Diego's ComicCon in popularity. It's spread across several neighboring hotels in the downtown area. A lot of the traffic funnels through the Marriot Marquis hotel, which has a large open area where, from above, you can see thousands of people at a time.And, with a laptop, see their broadcast packets.So I went up on a higher floor and setup my laptop in order to capture "probe" broadcasts coming from phones, in order to record the hardware MAC addresses. I've done this in years past, before address randomization, in order to record the popularity of iPhones. The first three bytes of an old-style, non-randomized address, identifies the manufacturer. This time, I should see a lot fewer manufacturer IDs, and mostly just random addresses instead.I recorded 9,095 unique probes over a couple hours. I'm not sure exactly how long -- my laptop would go to sleep occasionally because of lack of activity on the keyboard. I should probably setup a Raspberry Pi somewhere next year to get a more consistent result.A quick summary of the results are:The 9,000 devices were split almost evenly between Apple and Android. Almost all of the Apple devices randomized their addresses. About a third of the Android devices randomized. (This assumes Android only randomizes the final 3 bytes of the address, and that Apple tldr: I went to DragonCon, a conference of 85,000 people, so sniff WiFi packets and test how many phones now uses MAC address randomization. Almost all iPhones nowadays do, but it seems only a third of Android phones do.Ten years ago at BlackHat, we presented the "data seepage" problem, how the broadcasts from your devices allow you to be tracked. Among the things we highlighted was how WiFi probes looking to connect to access-points expose the unique hardware address burned into the phone, the MAC address. This hardware address is unique to your phone, shared by no other device in the world. Evildoers, such as the NSA or GRU, could install passive listening devices in airports and train-stations around the world in order to track your movements. This could be done with $25 devices sprinkled around a few thousand places -- within the budget of not only a police state, but also the average hacker.In 2014, with the release of iOS 8, Apple addressed this problem by randomizing the MAC address. Every time you restart your phone, it picks a new, random, hardware address for connecting to WiFi. This causes a few problems: every time you restart your iOS devices, your home network sees a completely new device, which can fill up your router's connection table. Since that table usually has at least 100 entries, this shouldn't be a problem for your home, but corporations and other owners of big networks saw their connection tables suddenly get big with iOS 8.In 2015, Google added the feature to Android as well. However, even though most Android phones today support this feature in theory, it's usually not enabled.Recently, I went to DragonCon in order to test out how well this works. DragonCon is a huge sci-fi/fantasy conference in Atlanta in August, second to San Diego's ComicCon in popularity. It's spread across several neighboring hotels in the downtown area. A lot of the traffic funnels through the Marriot Marquis hotel, which has a large open area where, from above, you can see thousands of people at a time.And, with a laptop, see their broadcast packets.So I went up on a higher floor and setup my laptop in order to capture "probe" broadcasts coming from phones, in order to record the hardware MAC addresses. I've done this in years past, before address randomization, in order to record the popularity of iPhones. The first three bytes of an old-style, non-randomized address, identifies the manufacturer. This time, I should see a lot fewer manufacturer IDs, and mostly just random addresses instead.I recorded 9,095 unique probes over a couple hours. I'm not sure exactly how long -- my laptop would go to sleep occasionally because of lack of activity on the keyboard. I should probably setup a Raspberry Pi somewhere next year to get a more consistent result.A quick summary of the results are:The 9,000 devices were split almost evenly between Apple and Android. Almost all of the Apple devices randomized their addresses. About a third of the Android devices randomized. (This assumes Android only randomizes the final 3 bytes of the address, and that Apple |
||||
| 2017-08-22 22:48:09 | ROI is not a cybersecurity concept (lien direct) | In the cybersecurity community, much time is spent trying to speak the language of business, in order to communicate to business leaders our problems. One way we do this is trying to adapt the concept of "return on investment" or "ROI" to explain why they need to spend more money. Stop doing this. It's nonsense. ROI is a concept pushed by vendors in order to justify why you should pay money for their snake oil security products. Don't play the vendor's game.The correct concept is simply "risk analysis". Here's how it works.List out all the risks. For each risk, calculate:How often it occurs.How much damage it does.How to mitigate it.How effective the mitigation is (reduces chance and/or cost).How much the mitigation costs.If you have risk of something that'll happen once-per-day on average, costing $1000 each time, then a mitigation costing $500/day that reduces likelihood to once-per-week is a clear win for investment.Now, ROI should in theory fit directly into this model. If you are paying $500/day to reduce that risk, I could use ROI to show you hypothetical products that will ......reduce the remaining risk to once-per-month for an additional $10/day....replace that $500/day mitigation with a $400/day mitigation.But this is never done. Companies don't have a sophisticated enough risk matrix in order to plug in some ROI numbers to reduce cost/risk. Instead, ROI is a calculation is done standalone by a vendor pimping product, or a security engineer building empires within the company.If you haven't done risk analysis to begin with (and almost none of you have), then ROI calculations are pointless.But there are further problems. This is risk analysis as done in industries like oil and gas, which have inanimate risk. Almost all their risks are due to accidental failures, like in the Deep Water Horizon incident. In our industry, cybersecurity, risks are animate -- by hackers. Our risk models are based on trying to guess what hackers might do.An example of this problem is when our drug company jacks up the price of an HIV drug, Anonymous hackers will break in and dump all our financial data, and our CFO will go to jail. A lot of our risks come now from the technical side, but the whims and fads of the hacker community.Another example is when some Google researcher finds a vuln in WordPress, and our website gets hacked by that three months from now. We have to forecast not only what hackers can do now, but what they might be able to do in the future.Finally, there is this problem with cybersecurity that we really can't distinguish between pesky and existential threats. Take ransomware. A lot of large organizations have just gotten accustomed to just wiping a few worker's machines every day and restoring from backups. It's a small, pesky problem of little consequence. Then one day a ransomware gets domain admin privileges and takes down the entire business for several weeks, as happened after #nPetya. Inevitably our risk models always come down on the high side of estimates, with us claiming that all threats are existential, when in fact, most companies continue to survive major breaches.These difficulties with risk analysis leads us to punting on the problem altogether, but that's not the right answer. No matter how faulty our risk analysis is, we still have to go through the exercise.One model of how to do this calculation is architecture. We know we need a certain number of toilets per building, even without doing ROI on the value of such toilets. The same is true for a lot of security engineering. We know we need firewalls, encryption, and OWASP hardening, even without specifically doing a calculation. Passwords and session cookies need to go across SSL. That's the starting point from which we start to analysis risks and mitigations -- what we need b | Guideline | |||
| 2017-08-19 18:18:25 | On ISO standardization of blockchains (lien direct) | So ISO, the primary international standards organization, is seeking to standardize blockchain technologies. On the surface, this seems a reasonable idea, creating a common standard that everyone can interoperate with.But it can be silly idea in practice. I mean, it should not be assumed that this is a good thing to do.The value of official standardsYou don't need the official imprimatur of a government committee for something to be a "standard". The Internet itself is a prime example of that.In the 1980s, the ISO and the IETF (Internet Engineering Task Force) pursued competing standards for creating a world-wide "internet". The IETF was an informal group of technologist that had essentially no official standing.The ISO version of the Internet failed. Their process was to bring multiple stakeholders from business, government, and universities together in committees to debate competing interests. The result was something so horrible that it could never work in practice.The IETF succeeded. It consisted of engineers just building things. Rather than officially "standardized", these things were "described", so that others knew enough to build their own version that interoperated. Once lots of different people built interoperating versions of something, then it became a "standard".In other words, the way the Internet came to be, standardization followed interoperability -- it didn't create interoperability.In the end, the ISO gave up on their standards and adopted the IETF standards. The ISO brought no value to the development of Internet standards. Whether they ratified the Internet's "TCP/IP" standard, ignored it, or condemned it, the Internet would exist today anyway, and a competing ISO-blessed internetwork would not.The same question exists for blockchain technologies. Groups are off busy innovating quickly, creating their own standards. If the ISO blesses one, or creates its own, it's unlikely to have any impact on interoperability.Blockchain vs. chaining blocksThe excitement over blockchains is largely driven by people who don't know the details, who don't understand the difference between a blockchain like Bitcoin and the problem they are trying to solve.Consider a record keeping system, especially public records. Storing them in a blockchain seems like a natural idea.But in fact, it's a terrible idea. A Bitcoin-style blockchain has a lot of features you don't want, like "proof-of-work" signing. It is also missing necessary features, like bulk storage with redundancy (backups). Sure, Bitcoin has redundancy, but by brute force, storing the blockchain in thousands of places around the Internet. This is far from what a public records system would need, which would store a lot more data with far fewer backup copies (fewer than 10).The only real overlap between Bitcoin and a public records system is a "signing chain". But this is something that already existed before Bitcoin. It's what Bitcoin blockchain was built on top of -- it's not the blockchain itself.It's like people discovering "cryptography" for the first time when they looked at Bitcoin, ignoring the thousand year history of crypto, and now every time they see a need for "crypto" they think "Bitcoin blockchain".Consensus and forkingThe entire point of Bitcoin, the reason it was created, was as the antithesis to centralized standardization like ISO. Standardizing blockchains misses the entire point of their existence. The Bitcoin manifesto is that standardization comes from acclamation not proclamation, and that many different standards are preferable to a single one.This is not just a theoretical idea but one built into Bitcoin's blockchain technology. "Consensus" is achieved by the proof-of-work mechanism, so that those who do the most work are the ones that drive the consensus. When irreconcilable differences arise, the | ||||
| 2017-08-18 16:29:15 | Announcement: IPS code (lien direct) | So after 20 years, IBM is killing off my BlackICE code created in April 1998. So it's time that I rewrite it.BlackICE was the first "inline" intrusion-detection system, aka. an "intrusion prevention system" or IPS. ISS purchased my company in 2001 and replaced their RealSecure engine with it, and later renamed it Proventia. Then IBM purchased ISS in 2006. Now, they are formally canceling the project and moving customers onto Cisco's products, which are based on Snort.So now is a good time to write a replacement. The reason is that BlackICE worked fundamentally differently than Snort, using protocol analysis rather than pattern-matching. In this way, it worked more like Bro than Snort. The biggest benefit of protocol-analysis is speed, making it many times faster than Snort. The second benefit is better detection ability, as I describe in this post on Heartbleed.So my plan is to create a new project. I'll be checking in the starter bits into GitHub starting a couple weeks from now. I need to figure out a new name for the project, so I don't have to rip off a name from William Gibson like I did last time :).Some notes:Yes, it'll be GNU open source. I'm a capitalist, so I'll earn money like snort/nmap dual-licensing it, charging companies who don't want to open-source their addons. All capitalists GNU license their code.C, not Rust. Sorry, I'm going for extreme scalability. We'll re-visit this decision later when looking at building protocol parsers.It'll be 95% compatible with Snort signatures. Their language definition leaves so much ambiguous it'll be hard to be 100% compatible.It'll support Snort output as well, though really, Snort's events suck.Protocol parsers in Lua, so you can use it as a replacement for Bro, writing parsers to extract data you are interested in.Protocol state machine parsers in C, like you see in my Masscan project for X.509.First version IDS only. These days, "inline" means also being able to MitM the SSL stack, so I'm gong to have to think harder on that.Mutli-core worker threads off PF_RING/DPDK/netmap receive queues. Should handle 10gbps, tracking 10 million concurrent connections, with quad-core CPU.So if you want to contribute to the project, here's what I need:Requirements from people who work daily with IDS/IPS today. I need you to write up what your products do well that you really like. I need to you write up what they suck at that needs to be fixed. These need to be in some detail.Testing environment to play with. This means having a small server plugged into a real-world link running at a minimum of several gigabits-per-second available for the next year. I'll sign NDAs related to the data I might see on the network.Coders. I'll be doing the basic architecture, but protocol parsers, output plugins, etc. will need work. Code will be in C and Lua for the near term. Unfortunately, since I'm going to dual-license, I'll need waivers before accepting pull requests.Anyway, follow me on Twitter @erratarob if you want to contribute. | ||||
| 2017-08-15 02:02:02 | Why that "file-copy" forensics of DNC hack is wrong (lien direct) | People keep asking me about this story about how forensics "experts" have found proof the DNC hack was an inside job, because files were copied at 22-megabytes-per-second, faster than is reasonable for Internet connections.This story is bogus.Yes, the forensics is correct that at some point, files were copied at 22-mBps. But there's no evidence this was the point at Internet transfer out of the DNC.One point might from one computer to another within the DNC. Indeed, as someone experienced doing this sort of hack, it's almost certain that at some point, such a copy happened. The computers you are able to hack into are rarely the computers that have the data you want. Instead, you have to copy the data from other computers to the hacked computer, and then exfiltrate the data out of the hacked computer.Another point might have been from one computer to another within the hacker's own network, after the data was stolen. As a hacker, I can tell you that I frequently do this. Indeed, as this story points out, the timestamps of the file shows that the 22-mBps copy happened months after the hack was detected.If the 22-mBps was the copy exfiltrating data, it might not have been from inside the DNC building, but from some cloud service, as this tweet points out. Hackers usually have "staging" servers in the cloud that can talk to other cloud serves at easily 10 times the 22-mBps, even around the world. I have staging servers that will do this, and indeed, have copied files at this data rate. If the DNC had that data or backups in the cloud, this would explain it. My point is that while the forensic data-point is good, there's just a zillion ways of explaining it. It's silly to insist on only the one explanation that fits your pet theory.As a side note, you can tell this already from the way the story is told. For example, rather than explain the evidence and let it stand on its own, the stories hype the credentials of those who believe the story, using the "appeal to authority" fallacy. | ||||
| 2017-08-06 21:31:52 | Query name minimization (lien direct) | One new thing you need to add your DNS security policies is "query name minimizations" (RFC 7816). I thought I'd mention it since many haven't heard about it.Right now, when DNS resolvers lookup a name like "www.example.com.", they send the entire name to the root server (like a.root-servers.net.). When it gets back the answer to the .com DNS server a.gtld-servers.net), it then resends the full "www.example.com" query to that server.This is obviously unnecessary. The first query should be just .com. to the root server, then example.com. to the next server -- the minimal amount needed for each query, not the full query.The reason this is important is that everyone is listening in on root name server queries. Universities and independent researchers do this to maintain the DNS system, and to track malware. Security companies do this also to track malware, bots, command-and-control channels, and so forth. The world's biggest spy agencies do this in order just to spy on people. Minimizing your queries prevents them from spying on you.An example where this is important is that story of lookups from AlfaBank in Russia for "mail1.trump-emails.com". Whatever you think of Trump, this was an improper invasion of privacy, where DNS researchers misused their privileged access in order to pursue their anti-Trump political agenda. If AlfaBank had used query name minimization, none of this would have happened.It's also critical for not exposing internal resources. Even when you do "split DNS", when the .com record expires, you resolver will still forward the internal DNS record to the outside world. All those Russian hackers can map out the internal names of your network simply by eavesdropping on root server queries.Servers that support this are Knot resolver and Unbound 1.5.7+ and possibly others. It's a relatively new standard, so it make take a while for other DNS servers to support this. | ||||
| 2017-08-01 00:06:00 | Top 10 Most Obvious Hacks of All Time (v0.9) (lien direct) | For teaching hacking/cybersecurity, I thought I'd create of the most obvious hacks of all time. Not the best hacks, the most sophisticated hacks, or the hacks with the biggest impact, but the most obvious hacks -- ones that even the least knowledgeable among us should be able to understand. Below I propose some hacks that fit this bill, though in no particular order.The reason I'm writing this is that my niece wants me to teach her some hacking. I thought I'd start with the obvious stuff first.Shared PasswordsIf you use the same password for every website, and one of those websites gets hacked, then the hacker has your password for all your websites. The reason your Facebook account got hacked wasn't because of anything Facebook did, but because you used the same email-address and password when creating an account on "beagleforums.com", which got hacked last year.I've heard people say "I'm sure, because I choose a complex password and use it everywhere". No, this is the very worst thing you can do. Sure, you can the use the same password on all sites you don't care much about, but for Facebook, your email account, and your bank, you should have a unique password, so that when other sites get hacked, your important sites are secure.And yes, it's okay to write down your passwords on paper.PIN encrypted PDFsMy accountant emails PDF statements encrypted with the last 4 digits of my Social Security Number. This is not encryption -- a 4 digit number has only 10,000 combinations, and a hacker can guess all of them in seconds.PIN numbers for ATM cards work because ATM machines are online, and the machine can reject your card after four guesses. PIN numbers don't work for documents, because they are offline -- the hacker has a copy of the document on their own machine, disconnected from the Internet, and can continue making bad guesses with no restrictions.Passwords protecting documents must be long enough that even trillion upon trillion guesses are insufficient to guess.SQL and other injectionThe lazy way of combining websites with databases is to combine user input with an SQL statement. This combines code with data, so the obvious consequence is that hackers can craft data to mess with the code.No, this isn't obvious to the general public, but it should be obvious to programmers. The moment you write code that adds unfiltered user-input to an SQL statement, the consequence should be obvious. Yet, "SQL injection" has remained one of the most effective hacks for the last 15 years because somehow programmers don't understand the consequence.CGI shell injection is a similar issue. Back in early days, when "CGI scripts" were a thing, it was really important, but these days, not so much, so I just included it with SQL. The consequence of executing shell code should've been obvious, but weirdly, it wasn't. The IT guy at the company I worked for back in the late 1990s came to me and asked "this guy says we have a vulnerability, is he full of shit?", and I had to answer "no, he's right -- obviously so".XSS ("Cross Site Scripting") [*] is another injection issue, but this time at somebody's web browser rather than a server. It works because websites will echo back what is sent to them. For example, if you search for Cross Site Scripting with the URL https://www.google.com/search?q=cross+site+scripting, then you'll get a page back from the server that contains that string. If the string is JavaScript code rather than text, then some servers (thought not Google) send back the code in the page in a way that it'll be executed. This is most often used to hack somebody's account: you send them an e | ||||
| 2017-07-29 16:27:26 | Is DefCon Wifi safe? (lien direct) | DEF CON is the largest U.S. hacker conference that takes place every summer in Las Vegas. It offers WiFi service. Is it safe?Probably.The trick is that you need to download the certificate from https://wifireg.defcon.org and import it into your computer. They have instructions for all your various operating systems. For macOS, it was as simple as downloading "dc25.mobileconfig" and importing it.I haven't validated the DefCon team did the right thing for all platforms, but I know that safety is possible. If a hacker could easily hack into arbitrary WiFi, then equipment vendors would fix it. Corporations widely use WiFi -- they couldn't do this if it weren't safe.The first step in safety is encryption, obviously. WPA does encryption well, you you are good there.The second step is authentication -- proving that the access-point is who it says it is. Otherwise, somebody could setup their own access-point claiming to be "DefCon", and you'd happily connect to it. Encrypted connect to the evil access-point doesn't help you. This is what the certificate you download does -- you import it into your system, so that you'll trust only the "DefCon" access-point that has the private key.That's not to say you are completely safe. There's a known vulnerability for the Broadcom WiFi chip imbedded in many devices, including iPhone and Android phones. If you have one of these devices, you should either upgrade your software with a fix or disable WiFi.There may also be unknown vulnerabilities in WiFi stacks. the Broadcom bug shows that after a couple decades, we still haven't solved the problem of simple buffer overflows in WiFi stacks/drivers. Thus, some hacker may have an unknown 0day vulnerability they are using to hack you.Of course, this can apply to any WiFi usage anywhere. Frankly, if I had such an 0day, I wouldn't use it at DefCon. Along with black-hat hackers DefCon is full of white-hat researchers monitoring the WiFi -- looking for hackers using exploits. They are likely to discover the 0day and report it. Thus, I'd rather use such 0-days in international airpots, catching business types, getting into their company secrets. Or, targeting government types.So it's impossible to guarantee any security. But what the DefCon network team bas done looks right, the same sort of thing corporations do to secure themselves, so you are probably secure.On the other hand, don't use "DefCon-Open" -- not only is it insecure, there are explicitly a ton of hackers spying on it at the "Wall of Sheep" to point out the "sheep" who don't secure their passwords. |
||||
| 2017-07-26 19:52:06 | Slowloris all the things (lien direct) | At DEFCON, some researchers are going to announce a Slowloris-type exploit for SMB -- SMBloris. I thought I'd write up some comments.The original Slowloris from several years creates a ton of connections to a web server, but only sends partial headers. The server allocates a large amount of memory to handle the requests, expecting to free that memory soon when the requests are completed. But the requests are never completed, so the memory remains tied up indefinitely. Moreover, this also consumes a lot of CPU resources -- every time Slowloris dribbles a few more bytes on the TCP connection is forces the CPU to walk through a lot of data structures to handle those bytes.The thing about Slowloris is that it's not specific to HTTP. It's a principle that affects pretty much every service that listens on the Internet. For example, on Linux servers running NFS, you can exploit the RPC fragmentation feature in order to force the server to allocate all the memory in a box waiting for fragments that never arrive.SMBloris does the same thing for SMB. It's an easy attack to carry out in general, the only question is how much resources are required on the attacker's side. That's probably what this talk is about, causing the maximum consequences on the server with minimal resources on the attacker's machine, thus allowing a Raspberry Pi to tie up all the resources on even the largest enterprise server.According to the ThreatPost article, the attack was created looking at the NSA ETERNALBLUE exploit. That exploit works by causing the server to allocate memory chunks from fragmented requests. How to build a Slowloris exploit from this is then straightforward -- just continue executing the first part of the ETERNALBLUE exploit, with larger chunks. I say "straightforward", but of course, the researchers have probably discovered some additional clever tricks.Samba, the SMB rewrite for non-Windows systems, probably falls victim to related problems. Maybe not this particular attack that affects Windows, but almost certainly something else. If not SMB, then the DCE-RPC service on top of it.Microsoft has said they aren't going to fix the SMBloris bug, and for good reason: it might be unfixable. Sure, there's probably some kludge that fixes this specific script, but would still leave the system vulnerable to slight variations. The same reasoning applies to other services -- Slowloris is an inherent problem in all Internet services and is not something easily addressed without re-writing the service from the ground up to specifically deal with the problem.The best answer to Slowloris is the "langsec" discipline, which counsels us to separate "parsing" input from "processing" it. Most services combine the two, partially processing partial input. This should be changed to fully validate input consuming the least resources possible, before processing it. In other words, services should have a light-weight front-end that consumes the least resources possible, waiting for the request to complete, before it then forwards the request to the rest of the system. | ||||
| 2017-07-23 21:51:04 | Defending anti-netneutrality arguments (lien direct) | Last week, activists proclaimed a "NetNeutrality Day", trying to convince the FCC to regulate NetNeutrality. As a libertarian, I tweeted many reasons why NetNeutrality is stupid. NetNeutrality is exactly the sort of government regulation Libertarians hate most. Somebody tweeted the following challenge, which I thought I'd address here.@ErrataRob I'd like to see you defend your NN stance in this context.https://t.co/2yvwMLo1m1https://t.co/a7CYxd9vcW- Tanner Bennett (@NSExceptional) July 21, 2017The links point to two separate cases.the Comcast BitTorrent throttling casea lawsuit against Time Warning for poor serviceThe tone of the tweet suggests that my anti-NetNeutrality stance cannot be defended in light of these cases. But of course this is wrong. The short answers are:the Comcast BitTorrent throttling benefits customerspoor service has nothing to do with NetNeutralityThe long answers are below.The Comcast BitTorrent ThrottlingThe presumption is that any sort of packet-filtering is automatically evil, and against the customer's interests. That's not true.Take GoGoInflight's internet service for airplanes. They block access to video sites like NetFlix. That's because they often have as little as 1-mbps for the entire plane, which is enough to support many people checking email and browsing Facebook, but a single person trying to watch video will overload the internet connection for everyone. Therefore, their Internet service won't work unless they filter video sites.GoGoInflight breaks a lot of other NetNeutrality rules, such as providing free access to Amazon.com or promotion deals where users of a particular phone get free Internet access that everyone else pays for. And all this is allowed by FCC, allowing GoGoInflight to break NetNeutrality rules because it's clearly in the customer interest.Comcast's throttling of BitTorrent is likewise clearly in the customer interest. Until the FCC stopped them, BitTorrent users were allowed unlimited downloads. Afterwards, Comcast imposed a 300-gigabyte/month bandwidth cap.Internet access is a series of tradeoffs. BitTorrent causes congestion during prime time (6pm to 10pm). Comcast has to solve it somehow -- not solving it wasn't an option. Their options were:Charge all customers more, so that the 99% not using BitTorrent subsidizes the 1% who do.Impose a bandwidth cap, preventing heavy BitTorrent usage.Throttle BitTorrent packets during prime-time hours when the network is congested.Option 3 is clearly the best. BitTorrent downloads take hours, days, and sometimes weeks. BitTorrent users don't mind throttling during prime-time congested hours. That's preferable to the other option, bandwidth caps.I'm a BitTorrent user, and a heavy downloader (I scan the Internet on a regular basis from cloud machines, then download the results to home, which can often be 100-gigabytes in size for a single scan). I want prime-time BitTorrent throttling rather than bandwidth caps. The EFF/FCC's action that prevented BitTorrent throttling forced me to move to Comcast Business Class which doesn't have bandwidth caps, charging me $100 more a month. It's why I don't contribute the EFF -- if they had not agitated for this, taking such choices away from customers, I'd have $1200 more per year to donate to worthy causes.Ask any user of BitTorrent which they prefer: 30 | Guideline | |||
| 2017-07-08 23:14:23 | Burner laptops for DEF CON (lien direct) | Hacker summer camp (Defcon, Blackhat, BSidesLV) is upon us, so I thought I'd write up some quick notes about bringing a "burner" laptop. Chrome is your best choice in terms of security, but I need Windows/Linux tools, so I got a Windows laptop.I chose the Asus e200ha for $199 from Amazon with free (and fast) shipping. There are similar notebooks with roughly the same hardware and price from other manufacturers (HP, Dell, etc.), so I'm not sure how this compares against those other ones. However, it fits my needs as a "burner" laptop, namely:cheaplasts 10 hours easily on batteryweighs 2.2 pounds (1 kilogram)11.6 inch and thinSome other specs are:4 gigs of RAM32 gigs of eMMC flash memoryquad core 1.44 GHz Intel Atom CPUWindows 10free Microsoft Office 365 for one yeargood, large keyboardgood, large touchpadUSB 3.0microSDWiFi acno fans, completely silentThere are compromises, of course.The Atom CPU is slow, thought it's only noticeable when churning through heavy webpages. Adblocking addons or Brave are a necessity. Most things are usably fast, such as using Microsoft Word.Crappy sound and video, though VLC does a fine job playing movies with headphones on the airplane. Using in bright sunlight will be difficult.micro-HDMI, keep in mind if intending to do presos from it, you'll need an HDMI adapterIt has limited storage, 32gigs in theory, about half that usable.Does special Windows 10 compressed install that you can't actually upgrade without a completely new install. It doesn't have the latest Windows 10 Creators update. I lost a gig thinking I could compress system files.Copying files across the 802.11ac WiFi to the disk was quite fast, several hundred megabits-per-second. The eMMC isn't as fast as an SSD, but its a lot faster than typical SD card speeds.The first thing I did once I got the notebook was to install the free VeraCrypt full disk encryption. The CPU has AES acceleration, so it's fast. There is a problem with the keyboard driver during boot that makes it really hard to enter long passwords -- you have to carefully type one key at a time to prevent extra keystrokes from being entered.You can't really install Linux on this computer, but you can use virtual machines. I installed VirtualBox and downloaded the Kali VM. I had some problems attaching USB devices to the VM. First of all, VirtualBox requires a separate downloaded extension to get USB working. Second, it conflicts with USBpcap that I installed for Wireshark.It comes with one year of free Office 365. Obviously, Microsoft is hoping to hook the user into a longer term commitment, but in practice next year at this time I'd get another burner $200 laptop rather than spend $99 on extending the Office 365 license.Let's talk about the CPU. It's Intel's "Atom" processor, not their mainstream (Core i3 etc.) processor. Even though it has roughly the same GHz as the processor in a 11inch MacBook Air and twice the cores, it's noticeably and painfully slower. This is especially noticeable on ad-heavy web pages, while other things seem to work just fine. It has hardware acceleration for most video formats, though I had trouble getting Netflix to work.The tradeoff fo | ||||
| 2017-07-01 20:21:20 | Yet more reasons to disagree with experts on nPetya (lien direct) |  In WW II, they looked at planes returning from bombing missions that were shot full of holes. Their natural conclusion was to add more armor to the sections that were damaged, to protect them in the future. But wait, said the statisticians. The original damage is likely spread evenly across the plane. Damage on returning planes indicates where they could damage and still return. The undamaged areas are where they were hit and couldn't return. Thus, it's the undamaged areas you need to protect.This is called survivorship bias.Many experts are making the same mistake with regards to the nPetya ransomware. I hate to point this out, because they are all experts I admire and respect, especially @MalwareJake, but it's still an error. An example is this tweet:Errors happen. But look at the discipline put into the spreading code. That worked as intended. Only the ransomware components have bugs?- Jake Williams (@MalwareJake) July 1, 2017The context of this tweet is the discussion of why nPetya was well written with regards to spreading, but full of bugs with regards to collecting on the ransom. The conclusion therefore that it wasn't intended to be ransomware, but was intended to simply be a "wiper", to cause destruction.But this is just survivorship bias. If nPetya had been written the other way, with excellent ransomware features and poor spreading, we would not now be talking about it. Even that initial seeding with the trojaned MeDoc update wouldn't have spread it far enough.In other words, all malware samples we get are good at spreading, either on their own, or because the creator did a good job seeding them. It's because we never see the ones that didn't spread.With regards to nPetya, a lot of experts are making this claim. Since it spread so well, but had hopelessly crippled ransomware features, that must have been the intent all along. Yet, as we see from survivorship bias, none of us would've seen nPetya had it not been for the spreading feature. In WW II, they looked at planes returning from bombing missions that were shot full of holes. Their natural conclusion was to add more armor to the sections that were damaged, to protect them in the future. But wait, said the statisticians. The original damage is likely spread evenly across the plane. Damage on returning planes indicates where they could damage and still return. The undamaged areas are where they were hit and couldn't return. Thus, it's the undamaged areas you need to protect.This is called survivorship bias.Many experts are making the same mistake with regards to the nPetya ransomware. I hate to point this out, because they are all experts I admire and respect, especially @MalwareJake, but it's still an error. An example is this tweet:Errors happen. But look at the discipline put into the spreading code. That worked as intended. Only the ransomware components have bugs?- Jake Williams (@MalwareJake) July 1, 2017The context of this tweet is the discussion of why nPetya was well written with regards to spreading, but full of bugs with regards to collecting on the ransom. The conclusion therefore that it wasn't intended to be ransomware, but was intended to simply be a "wiper", to cause destruction.But this is just survivorship bias. If nPetya had been written the other way, with excellent ransomware features and poor spreading, we would not now be talking about it. Even that initial seeding with the trojaned MeDoc update wouldn't have spread it far enough.In other words, all malware samples we get are good at spreading, either on their own, or because the creator did a good job seeding them. It's because we never see the ones that didn't spread.With regards to nPetya, a lot of experts are making this claim. Since it spread so well, but had hopelessly crippled ransomware features, that must have been the intent all along. Yet, as we see from survivorship bias, none of us would've seen nPetya had it not been for the spreading feature. |
★★★★★ | |||
| 2017-06-29 20:25:53 | NonPetya: no evidence it was a "smokescreen" (lien direct) | Many well-regarded experts claim that the not-Petya ransomware wasn't "ransomware" at all, but a "wiper" whose goal was to destroy files, without any intent at letting victims recover their files. I want to point out that there is no real evidence of this.Certainly, things look suspicious. For one thing, it certainly targeted the Ukraine. For another thing, it made several mistakes that prevent them from ever decrypting drives. Their email account was shutdown, and it corrupts the boot sector.But these things aren't evidence, they are problems. They are things needing explanation, not things that support our preferred conspiracy theory.The simplest, Occam's Razor explanation explanation is that they were simple mistakes. Such mistakes are common among ransomware. We think of virus writers as professional software developers who thoroughly test their code. Decades of evidence show the opposite, that such software is of poor quality with shockingly bad bugs.It's true that effectively, nPetya is a wiper. Matthieu Suiche†does a great job describing one flaw that prevents it working. @hasherezade does a great job explaining another flaw. But best explanation isn't that this is intentional. Even if these bugs didn't exist, it'd still be a wiper if the perpetrators simply ignored the decryption requests. They need not intentionally make the decryption fail.Thus, the simpler explanation is that it's simply a bug. Ransomware authors test the bits they care about, and test less well the bits they don't. It's quite plausible to believe that just before shipping the code, they'd add a few extra features, and forget to regression test the entire suite. I mean, I do that all the time with my code.Some have pointed to the sophistication of the code as proof that such simple errors are unlikely. This isn't true. While it's more sophisticated than WannaCry, it's about average for the current state-of-the-art for ransomware in general. What people think of, such the Petya base, or using PsExec to spread throughout a Windows domain, is already at least a year old.Indeed, the use of PsExec itself is a bit clumsy, when the code for doing the same thing is already public. It's just a few calls to basic Windows networking APIs. A sophisticated virus would do this itself, rather than clumsily use PsExec.Infamy doesn't mean skill. People keep making the mistake that the more widespread something is in the news, the more skill, the more of a "conspiracy" there must be behind it. This is not true. Virus/worm writers often do newsworthy things by accident. Indeed, the history of worms, starting with the Morris Worm, has been things running out of control more than the author's expectations.What makes nPetya newsworthy isn't the EternalBlue exploit or the wiper feature. Instead, the creators got lucky with MeDoc. The software is used by every major organization in the Ukraine, and at the same time, their website was horribly insecure -- laughably insecure. Furthermore, it's autoupdate feature didn't check cryptographic signatures. No hacker can plan for this level of widespread incompetence -- it's just extreme luck.Thus, the effect of bumbling around is something that hit the Ukraine pretty hard, but it's not necessarily the intent of the creators. It's like how the Slammer worm hit South Korea pretty hard, or how the Witty worm hit the DoD pretty hard. These things look "targeted", especially to the victims, but it was by pure chance (provably so, in the case of Witty).Certainly, MeDoc was targeted. But then, targeting a s | Wannacry | |||
| 2017-06-25 23:23:44 | A kindly lesson for you non-techies about encryption (lien direct) | The following tweets need to be debunked: The answer to John Schindler's question is:every expert in cryptography doesn't know thisOh, sure, you can find fringe wacko who also knows crypto that agrees with you but all the sane members of the security community will not.Telegram is not trustworthy because it's partially closed-source. We can't see how it works. We don't know if they've made accidental mistakes that can be hacked. We don't know if they've been bribed by the NSA or Russia to put backdoors in their program. In contrast, PGP and Signal are open-source. We can read exactly what the software does. Indeed, thousands of people have been reviewing their software looking for mistakes and backdoors. Being open-source doesn't automatically make software better, but it does make hiding secret backdoors much harder.Telegram is not trustworthy because we aren't certain the crypto is done properly. Signal, and especially PGP, are done properly.The thing about encryption is that when done properly, it works. Neither the NSA nor the Russians can break properly encrypted content. There's no such thing as "military grade" encryption that is better than consumer grade. There's only encryption that nobody can hack vs. encryption that your neighbor's teenage kid can easily hack. Those scenes in TV/movies about breaking encryption is as realistic as sound in space: good for dramatic presentation, but not how things work in the real world.In particular, end-to-end encryption works. Sure, in the past, such apps only encrypted as far as the server, so whoever ran the server could read your messages. Modern chat apps, though, are end-to-end: the servers have absolutely no ability to decrypt what's on them, unless they can get the decryption keys from the phones. But some tasks, like encrypted messages to a group of people, can be hard to do properly.Thus, in contrast to what John Schindler says, while we techies have doubts about Telegram, we don't have doubts about Russia authorities having access to Signal and PGP messages.Snowden hatred has become the anti-vax of crypto. Sure, there's no particular reason to trust Snowden -- people should really stop treating him as some sort of privacy-Jesus. But there's no particular reason to distrust him, either. His bland statements on crypto are indistinguishable from any other crypto-enthusiast statements. If he's a Russian pawn, then so too is the bulk of the crypto community.With all this said, using Signal doesn't make you perfectly safe. The person you are chatting with could be a secret agent -- especially in group chat. There could be cameras/microphones in the room where you are using the app. The Russians can also hack into your phone, and likewise eavesdrop on everything you do with the phone, regardless of which app you use. And they probably have hacked specific people's phones. On the other hand, if the NSA or Russians were widely hacking phones, we'd detect that this was happening. We haven't.Signal is therefore not a guarantee of safety, because nothing is, and if your life depends on it, you can't trust any simple advice like "use Signal". But, for the bulk of us, it's pretty damn secure, and I trust neither the Russians nor the NSA are reading my Signal or PGP messages.At first blush, this @20committ The answer to John Schindler's question is:every expert in cryptography doesn't know thisOh, sure, you can find fringe wacko who also knows crypto that agrees with you but all the sane members of the security community will not.Telegram is not trustworthy because it's partially closed-source. We can't see how it works. We don't know if they've made accidental mistakes that can be hacked. We don't know if they've been bribed by the NSA or Russia to put backdoors in their program. In contrast, PGP and Signal are open-source. We can read exactly what the software does. Indeed, thousands of people have been reviewing their software looking for mistakes and backdoors. Being open-source doesn't automatically make software better, but it does make hiding secret backdoors much harder.Telegram is not trustworthy because we aren't certain the crypto is done properly. Signal, and especially PGP, are done properly.The thing about encryption is that when done properly, it works. Neither the NSA nor the Russians can break properly encrypted content. There's no such thing as "military grade" encryption that is better than consumer grade. There's only encryption that nobody can hack vs. encryption that your neighbor's teenage kid can easily hack. Those scenes in TV/movies about breaking encryption is as realistic as sound in space: good for dramatic presentation, but not how things work in the real world.In particular, end-to-end encryption works. Sure, in the past, such apps only encrypted as far as the server, so whoever ran the server could read your messages. Modern chat apps, though, are end-to-end: the servers have absolutely no ability to decrypt what's on them, unless they can get the decryption keys from the phones. But some tasks, like encrypted messages to a group of people, can be hard to do properly.Thus, in contrast to what John Schindler says, while we techies have doubts about Telegram, we don't have doubts about Russia authorities having access to Signal and PGP messages.Snowden hatred has become the anti-vax of crypto. Sure, there's no particular reason to trust Snowden -- people should really stop treating him as some sort of privacy-Jesus. But there's no particular reason to distrust him, either. His bland statements on crypto are indistinguishable from any other crypto-enthusiast statements. If he's a Russian pawn, then so too is the bulk of the crypto community.With all this said, using Signal doesn't make you perfectly safe. The person you are chatting with could be a secret agent -- especially in group chat. There could be cameras/microphones in the room where you are using the app. The Russians can also hack into your phone, and likewise eavesdrop on everything you do with the phone, regardless of which app you use. And they probably have hacked specific people's phones. On the other hand, if the NSA or Russians were widely hacking phones, we'd detect that this was happening. We haven't.Signal is therefore not a guarantee of safety, because nothing is, and if your life depends on it, you can't trust any simple advice like "use Signal". But, for the bulk of us, it's pretty damn secure, and I trust neither the Russians nor the NSA are reading my Signal or PGP messages.At first blush, this @20committ |
||||
| 2017-06-15 00:04:55 | Notes on open-sourcing abandoned code (lien direct) | Some people want a law that compels companies to release their source code for "abandoned software", in the name of cybersecurity, so that customers who bought it can continue to patch bugs long after the seller has stopped supporting the product. This is a bad policy, for a number of reasons.Code is SpeechFirst of all, code is speech. That was the argument why Phil Zimmerman could print the source code to PGP in a book, ship it overseas, and then have somebody scan the code back into a computer. Compelled speech is a violation of free speech. That was one of the arguments in the Apple vs. FBI case, where the FBI demanded that Apple write code for them, compelling speech.Compelling the opening of previously closed source is compelled speech. Sure, demanding new products come with source would be one thing, but going backwards demanding source for products sold before 2017 is quite another thing.For most people, "rights" are something that only their own side deserves. Whether something deserves the protection of "free speech" depends upon whether the speaker is "us" or the speaker is "them". If it's "them", then you'll find all sorts of reasons why their speech is a special case, and what it doesn't deserve protection.That's what's happening here. Open-source advocates have one idea of "code is speech" when it applies to them, and have another idea when applying to same principle to hated closed-source companies like Microsoft.Define abandonedWhat, precisely, does 'abandoned' mean? Consider Windows 3.1. Microsoft hasn't sold it for decades. Yet, it's not precisely abandoned either, because they still sell modern versions of Windows. Being forced to show even 30 year old source code would give competitors a significant advantage in creating Windows-compatible code like WINE.When code is truly abandoned, such as when the vendor has gone out of business, chances are good they don't have the original source code anyway. Thus, in order for this policy to have any effect, you'd have to force vendors to give a third-party escrow service a copy of their code whenever they release a new version of their product.All the source codeAnd that is surprisingly hard and costly. Most companies do not precisely know what source code their products are based upon. Yes, technically, all the code is in that ZIP file they gave to the escrow service, but it doesn't build. Essential build steps are missing, so that source code won't compile. It's like the dependency hell that many open-source products experience, such as downloading and installing two different versions of Python at different times during the build. Except, it's a hundred times worse.Often times building closed-source requires itself an obscure version of a closed-source tool that itself has been abandoned by its original vendor. You often times can't even define which is the source code. For example, engine control units (ECUs) are Matlab code that compiles down to C, which is then integrated with other C code, all of which is (using a special compiler) is translated to C. Unless you have all these closed source products, some of which are no longer sold, the source-code to the ECU will not help you in patch bugs.For small startups running fast, such as off Kickstarter, forcing them to escrow code that actually builds would force upon them an undue burden, harming innovation.Binary patch and reversingThen there is the issue of why you need the source code in the first place. Here's the deal with binary exploits like buffer-overflows: if you know enough to exploit it, you know enough to patch it. Just add some binary code onto the end of the function the program that verifies the input, then replace where the vulnerability happens to a jump instruction to the new code.I know this is possible and fairly trivi | ||||
| 2017-06-13 01:26:00 | More notes on US-CERTs IOCs (lien direct) | Yet another Russian attack against the power grid, and yet more bad IOCs from the DHS US-CERT.IOCs are "indicators of compromise", things you can look for in order to order to see if you, too, have been hacked by the same perpetrators. There are several types of IOCs, ranging from the highly specific to the uselessly generic.A uselessly generic IOC would be like trying to identify bank robbers by the fact that their getaway car was "white" in color. It's worth documenting, so that if the police ever show up in a suspected cabin in the woods, they can note that there's a "white" car parked in front.But if you work bank security, that doesn't mean you should be on the lookout for "white" cars. That would be silly.This is what happens with US-CERT's IOCs. They list some potentially useful things, but they also list a lot of junk that waste's people's times, with little ability to distinguish between the useful and the useless.An example: a few months ago was the GRIZZLEYBEAR report published by US-CERT. Among other things, it listed IP addresses used by hackers. There was no description which would be useful IP addresses to watch for, and which would be useless.Some of these IP addresses were useful, pointing to servers the group has been using a long time as command-and-control servers. Other IP addresses are more dubious, such as Tor exit nodes. You aren't concerned about any specific Tor exit IP address, because it changes randomly, so has no relationship to the attackers. Instead, if you cared about those Tor IP addresses, what you should be looking for is a dynamically updated list of Tor nodes updated daily.And finally, they listed IP addresses of Yahoo, because attackers passed data through Yahoo servers. No, it wasn't because those Yahoo servers had been compromised, it's just that everyone passes things though them, like email.A Vermont power-plant blindly dumped all those IP addresses into their sensors. As a consequence, the next morning when an employee checked their Yahoo email, the sensors triggered. This resulted in national headlines about the Russians hacking the Vermont power grid.Today, the US-CERT made similar mistakes with CRASHOVERRIDE. They took a report from Dragos Security, then mutilated it. Dragos's own IOCs focused on things like hostile strings and file hashes of the hostile files. They also included filenames, but similar to the reason you'd noticed a white car -- because it happened, not because you should be on the lookout for it. In context, there's nothing wrong with noting the file name.But the US-CERT pulled the filenames out of context. One of those filenames was, humorously, "svchost.exe". It's the name of an essential Windows service. Every Windows computer is running multiple copies of "svchost.exe". It's like saying "be on the lookout for Windows".Yes, it's true that viruses use the same filenames as essential Windows files like "svchost.exe". That's, generally, something you should be aware of. But that CRASHOVERRIDE did this is wholly meaningless.What Dragos Security was actually reporting was that a "svchost.exe" with the file hash of 79ca89711cdaedb16b0ccccfdcfbd6aa7e57120a was the virus -- it's the hash that's the important IOC. Pulling the filename out of context is just silly.Luckily, the DHS also provides some of the raw information provided by Dragos. But even then, there's problems: they provide it in formatted | Yahoo | |||
| 2017-06-06 20:24:44 | What about other leaked printed documents? (lien direct) | So nat-sec pundit/expert Marci Wheeler (@emptywheel) asks about those DIOG docs leaked last year. They were leaked in printed form, then scanned in an published by The Intercept. Did they have these nasty yellow dots that track the source? If not, why not?The answer is that the scanned images of the DIOG doc don't have dots. I don't know why. One reason might be that the scanner didn't pick them up, as it's much lower quality than the scanner for the Russian hacking docs. Another reason is that the printer used my not have printed them -- while most printers do print such dots, some printers don't. A third possibility is that somebody used a tool to strip the dots from scanned images. I don't think such a tool exists, but it wouldn't be hard to write.Scanner qualityThe printed docs are here. They are full of whitespace where it should be easy to see these dots, but they appear not to be there. If we reverse the image, we see something like the following from the first page of the DIOG doc: Compare this to the first page of the Russian hacking doc which shows the blue dots: Compare this to the first page of the Russian hacking doc which shows the blue dots: What we see in the difference is that the scan of the Russian doc is much better. We see that in the background, which is much noisier, able to pick small things like the blue dots. In contrast, the DIOG scan is worse. We don't see much detail in the background.Looking closer, we can see the lack of detail. We also see banding, which indicates other defects of the scanner. What we see in the difference is that the scan of the Russian doc is much better. We see that in the background, which is much noisier, able to pick small things like the blue dots. In contrast, the DIOG scan is worse. We don't see much detail in the background.Looking closer, we can see the lack of detail. We also see banding, which indicates other defects of the scanner. Thus, one theory is that the scanner just didn't pick up the dots from the page.Not all printersThe EFF has a page where they document which printers produce these dots. Samsung and Okidata don't, virtually all the other printers do.The person who printed these might've gotten lucky. Or, they may have carefully chosen a printer that does not produce these dots.The reason Reality Winner exfiltrated these documents by printing them is that the NSA had probably clamped down on USB thumb drives for secure facilities. Walking through the metal detector with a Thus, one theory is that the scanner just didn't pick up the dots from the page.Not all printersThe EFF has a page where they document which printers produce these dots. Samsung and Okidata don't, virtually all the other printers do.The person who printed these might've gotten lucky. Or, they may have carefully chosen a printer that does not produce these dots.The reason Reality Winner exfiltrated these documents by printing them is that the NSA had probably clamped down on USB thumb drives for secure facilities. Walking through the metal detector with a |
||||
| 2017-06-05 23:40:40 | How The Intercept Outed Reality Winner (lien direct) | Today, The Intercept released documents on election tampering from an NSA leaker. Later, the arrest warrant request for an NSA contractor named "Reality Winner" was published, showing how they tracked her down because she had printed out the documents and sent them to The Intercept. The document posted by the Intercept isn't the original PDF file, but a PDF containing the pictures of the printed version that was then later scanned in.The problem is that most new printers print nearly invisibly yellow dots that track down exactly when and where documents, any document, is printed. Because the NSA logs all printing jobs on its printers, it can use this to match up precisely who printed the document.In this post, I show how.You can download the document from the original article here. You can then open it in a PDF viewer, such as the normal "Preview" app on macOS. Zoom into some whitespace on the document, and take a screenshot of this. On macOS, hit [Command-Shift-3] to take a screenshot of a window. There are yellow dots in this image, but you can barely see them, especially if your screen is dirty. We need to highlight the yellow dots. Open the screenshot in an image editor, such as the "Paintbrush" program built into macOS. Now use the option to "Invert Colors" in the image, to get something like this. You should see a roughly rectangular pattern checkerboard in the whitespace. We need to highlight the yellow dots. Open the screenshot in an image editor, such as the "Paintbrush" program built into macOS. Now use the option to "Invert Colors" in the image, to get something like this. You should see a roughly rectangular pattern checkerboard in the whitespace. It's upside down, so we need to rotate it 180 degrees, or flip-horizontal and flip-vertical: It's upside down, so we need to rotate it 180 degrees, or flip-horizontal and flip-vertical: Now we go to the EFF page and manually click on the pattern so that their tool can decode the meaning: Now we go to the EFF page and manually click on the pattern so that their tool can decode the meaning: |
||||
| 2017-06-05 16:15:45 | Some non-lessons from WannaCry (lien direct) | This piece by Bruce Schneier needs debunking. I thought I'd list the things wrong with it.The NSA 0day debateSchneier's description of the problem is deceptive:When the US government discovers a vulnerability in a piece of software, however, it decides between two competing equities. It can keep it secret and use it offensively, to gather foreign intelligence, help execute search warrants, or deliver malware. Or it can alert the software vendor and see that the vulnerability is patched, protecting the country -- and, for that matter, the world -- from similar attacks by foreign governments and cybercriminals. It's an either-or choice.The government doesn't "discover" vulnerabilities accidentally. Instead, when the NSA has a need for something specific, it acquires the 0day, either through internal research or (more often) buying from independent researchers.The value of something is what you are willing to pay for it. If the NSA comes across a vulnerability accidentally, then the value to them is nearly zero. Obviously such vulns should be disclosed and fixed. Conversely, if the NSA is willing to pay $1 million to acquire a specific vuln for imminent use against a target, the offensive value is much greater than the fix value.What Schneier is doing is deliberately confusing the two, combing the policy for accidentally found vulns with deliberately acquired vulns.The above paragraph should read instead:When the government discovers a vulnerability accidentally, it then decides to alert the software vendor to get it patched. When the government decides it needs as vuln for a specific offensive use, it acquires one that meets its needs, uses it, and keeps it secret. After spending so much money acquiring an offensive vuln, it would obviously be stupid to change this decision and not use it offensively.Hoarding vulnsSchneier also says the NSA is "hoarding" vulns. The word has a couple inaccurate connotations.One connotation is that the NSA is putting them on a heap inside a vault, not using them. The opposite is true: the NSA only acquires vulns it for which it has an active need. It uses pretty much all the vulns it acquires. That can be seen in the ShadowBroker dump, all the vulns listed are extremely useful to attackers, especially ETERNALBLUE. Efficiency is important to the NSA. Your efficiency is your basis for promotion. There are other people who make their careers finding waste in the NSA. If you are hoarding vulns and not using them, you'll quickly get ejected from the NSA.Another connotation is that the NSA is somehow keeping the vulns away from vendors. That's like saying I'm hoarding naked selfies of myself. Yes, technically I'm keeping them away from you, but it's not like they ever belong to you in the first place. The same is true the NSA. Had it never acquired the ETERNALBLUE 0day, it never would've been researched, never found.The VEPSchneier describes the "Vulnerability Equities Process" or "VEP", a process that is supposed to manage the vulnerabilities the government gets.There's no evidence the VEP process has ever been used, at least not with 0days acquired by the NSA. The VEP allows exceptions for important vulns, and all the NSA vulns are important, so all are excepted from the process. Since the NSA is in charge of the VEP, of course, this is at the sole discretion of the NSA. Thus, the entire point of the VEP process goes away.Moreover, it can't work in many cases. The vulns acquired by the NSA often come with clauses that mean they can't be shared.New classes of vulnsOne reason sellers forbid 0days from being shared is because they use new classes of vulnerabilities, such that sha | Guideline | Wannacry |
{kind=link}
{kind=link}
To see everything:
Our RSS (filtrered)
